November 2006
Monthly Archive
Follow Up- Google Search
I wanted to make a quick follow up on the $100/day post in regards to monetizing the Google search. If you used the same screensaver program I use than this will be easy. If not then yo may need to make some modifications. Download any simple installer creation program. I’ve been using Setup Specialist for quite a few years now just because its super simple and quick. Create an installer for your screensaver. Copy over the self installing exe for the screensaver and then have it automatically execute immediately after the install finishes. There are two ways i know to pull some serious Google searches through your new install.
Desktop Search
This is the bit more technical way and since I have never actually done it I can’t go too specific on it. This will put a little google search box on their taskbar very similar to the Google Desktop Search. Go to Creating Custom Explorer Bars, Tool Bands, and Desk Bands and create the toolband. Then in the registry add the toolband to the taskbar. Like I said i’ve never done it but it doesn’t seem too hard to figure out. Use the Google search box that is easily created in your Adsense account
Changing Their Homepage
Create a small website that is something like myhomepage.com or greatstartpage.com, it doesn’t really matter what the url is. Make a snazzy but simple template and include the google search box on the page. Use the google search box that is easily created in your adsense account. Then in your installer program change the registry key HKEY_CURRENT_USER\SOFTWARE\Microsoft\Internet Explorer\Main\ change the “Start Page” to your new start page website address.
What will this do?
Everytime they search google you get proceeds from the adsense ads. As I’ll end up talking about in the upcoming Blue Hat Technique many internet users(especially the newbie ones) will never change their homepage. If it changes on them they will leave it. So you get small amounts of money over a very long period of time over massive amounts of users.
I was going to avoid this topic due to the new Blue Hat Technique coming out, but since this is extra info that won’t be covered in the post I figured I might as well get it out of the way.
Random Thoughts29 Nov 2006 05:12 pm
Get Down With The Sickness
Uhhhhhhg I have recently gotten very very sick. I never found the time to get my flu shots this year. Bad move on my part. 
However on the bright side, me getting sick somehow put me into a good mood. I may just be weird but for some reason I hate that feeling when you’re getting sick, but when I actually get sick and I just feel like utter crap, I get in a much better mood. Maybe its just knowing that the symptoms are the last phase of being sick. Eitherway I am back to my normal happy-go-lucky self and I am definitely back in the Christmas spirit. My body may be failing but my mental state is still strong. Despite the fact that no one wants to go near me and my germs this is definitely turning into a good week.
Going back to business. I got some really cool posts coming up. First will probably include my Complete Guide To Scraping Pt. 3. Which will detail the actual scraping of content and work seemlessly with the crawler script presented in Part 2. Soon after that will probably be the Wikipedia Links Pt. 4. Can you guess what that post will require knowledge of? Haha yep…scraping, and as promised to the Blackhatters it will be badass. Whether or not it will include the attached code is still being debated. The chances are not looking so good. Either way I know better than to doubt the brilliance and skills of the readers here so the code portion should be the easy part.
Speak of the devil! I’ve been getting emails from people who have finished coding Parts 2 and 3 from the Wikipedia Links series. I have also gotten TONS of emails from people wanting to buy the script from me. Just so you know, I WILL allow you to sell your builds in the comments. Just as long as everyone is honest and follows through I have no problems with people sharing and making a bit of cash from it.
Back on topic, I also got another Blue Hat technique I gotta throw into the mix sometime as well as a few white hat posts. I also got a massive post regarding free traffic ideas that was an idea emailed to me from a very benevolent reader here several months ago however I’m having a hard time finishing it. For some reason it just seems shitty (my writing not the idea). I’ll have to do a bit more work on it before I let you take a gander. Eitherway we have a very fun Christmas season coming up for the Blue Hatters (do you consider yourselves blue hatters YET?! nope? okay haha nevermind then). The only thing that will hang me up from getting all these posts out are which order to put them in. It all just seems too damn organized for my A.D.D. lovin’ tastes. I may just have to mix things up because confusing people is fun!
If you guys/gals have any ideas for a post you would like to see please be sure to either comment it up or email it to me. You all know how much I love fresh ideas and it would be a big help to me. My slow brain can only handle so much. 
Have A Great Christmas!
In the mean time entertain yourself with this awesome affiliate rap song from Eureka’s Diary
General Articles28 Nov 2006 12:32 am
Whitehats Guide To Massive Links
I’ll be blunt about it. Bitch bitch bitch is what I’ve been getting a lot of recently with the blackhat related posts. Ethics this and morals that. I don’t know who designated me as a shoulder to cry on in regards to personal hang ups but it really is getting very boring for me. This is an ideas and creativity site, not a debate site. So I’m just going to save the drama for yo mamma and continue focusing on the real issue, Internet Marketing. Whether that is black hat or white hat I really just don’t care. With this new leaf unturned lets talk about white hat ideas and methods that result in huge backlinks to your sites, and THANKFULLY will have nothing to do with link bait.
Huge Link Venues
CMS- Content management systems are vital to webmasters and where there are webmasters there are backlinks. To state the obvious, Wordpress.org & wordpress.com have huge amounts of backlinks for this very reason. Your CMS doesn’t necessarily have to be good it just has to be easy and popular. Sometimes simplicity will get you further than being rich in features. Your ultimate goal with creating and distributing a custom CMS you made should be getting it bundled where the webmasters will find it. Certain CMS didn’t become hugely popular until they convinced places like Cpanel to include them into their Fantastico section. If you can score this kind of publicity your in!
User Contributed Scripts- I’m not going to even talk about the power of forum type scripts because one look at vbulletin and others inbound links speak for themselves. You don’t have to aim that high, try something smaller like a Youtube replica script. How about a Digg replica? They are actually fairly easy to get custom made for you. Any freelancer website should find you a good amount of scripters that will make you one for less than $2k.
Promotion Tools- PhpLinkManager is a great example of this. A simple script that ppl put on thier site to manage their link exchanges. I could code something like this in less than an hour and continually get massive backlinks for years to come. How about something on your site? You don’t even have to share it you just have to give them a place to access it.
Templates- If you’re thinking the above is too hard and since your not a coder you feel a little left out, never forget the power of a solid template. Create a good contest winning Wordpress theme and your guaranteed thousands of high quality backlinks. I know one marketer that does nothing but create templates and submits them to free template sites. Part of the template download agreement is to leave the footer links intact. He has more backlinks than anyone I know. If your wanting some E-Com backlinks consider making a template for popular shopping scripts like Oscommerce or Cubecart. The promotion is easy. You just submit them to the site and watch as people use them.
Become A Manufacturer- You honestly didn’t think I was going to go this whole post without a single crazy crackpot idea did you? How about becoming a manufacturer for a crazy wacko product that is so exclusive not even you sell it. I saw a website awhile ago about a do it yourself lasic eye surgery kit. Was it a big joke or three steps above and beyond link bait? It doesn’t matter. It had damn good links and so did the three spammy pharmaceutical sites it linked to.
Become A Link Resource- I’m not going to specify placing a link directory on your site. This focus is on allowing webmasters to insert their own content in hopes of scoring some backlinks or sales themselves. How about an example? You create a mini shopping directory on your informational site. You list a ton of products and with each product you include a section on “What sites sell this product.” Link exchange factor aside you still score major links from every site and programs that show people how to promote their ecom sites and products. I’ve once done this by creating a software directory. I took a sneaky method. I told people that in order to submit their software they had to place a link back to another (more profitable) site of mine.
Content Solution- Become a solution to that pesky content problem. Examples of this range anywhere from Articledashboard to Youtube. Articledashboard created a complete site script that allows you to have your own articles directory. Needless to say it became very popular and now the site has massive links. Youtube, just as an example, allows webmasters to place individual videos on their site using simple “link code.” They even allow options for myspace and forums for non webmasters. Youtube is so huge it makes a bad example of this technique. Instead take a look at sites like Streetfire.com. Sites like this were built to huge proportions solely on this type of promotion.
Set an Example- I can’t help but be reminded of this old particular site. The specific example doesn’t matter, its what he did that counts. This guy took an extreme of a certain product genre and built it. He took pictures of the finished product and posted it up on his main site. From this point on every single site in his niche is now almost forced to link to his site simply because he had pictures of what every buyer in the niche dreams of.
Here comes my boring disclaimer that says this is just a few ideas and examples and coincidently encourages comments and pursues a creative brainstorming session. This sentence also usually includes a tip for the blackhatters but what the fucks the point? The next three posts or so are dedicated to them. 
I have to appologize in advanced. This busy ass Christmas season is slowly turning me into a grinch so I’m going to spare you the expected bullshit this time and this time only.
I’ll Get You Next Time Gadget!
Guides24 Nov 2006 01:49 pm
Complete Guide To Scraping Pt. 2 - Crawling
Well I hope everyone had a great thanksgiving. I love them turkey birds! I love them stuffed. I love them covered in gravy. I love the little gobbling noises they make.
Back to business. By now you should have at least a decent understand of what scraping is and how to use it. We just need to continue on to the next most obvious step, crawling. A crawler is a script that simply makes a list of all the pages on a site you would like to scrape. Creating a decent and versatile crawler is of the utmost importance. A good crawler will be not only thorough but will weed out a lot of the bullshit big sites tend to have. There are many different methods to crawling a site. It really is only limited to your imagination. The one I’m going to cover in this post isn’t the most efficient but it is very simple to understand and thorough.
Since I don’t feel like turning this post into a mysql tutorial I whipped up some quick code for a crawler script that will make a list of every page on a domain(supports subdomains) and put into a return delimited text file. Here is an example script that will crawl a website and make an index of all the pages. For you master coders out there; I realize there is more efficient ways to code this(especially the file scanning portion) but I was going for simplicity. So bear with me.
The Script
Crawler.cgi
How To Use
copy and paste the code into notepad and save it as crawler.cgi. Change the variables at the top. If you would like to exclude all the subdomains on the site include the www. infront of the domain. If not then just leave it as the domain. Be very careful with the crawl dynamic option. With the crawl dynamic on certain sites will cause this script to run for a VERY long time. In any crawler you design or use it is also a very good idea to set a limit to the maximum number of pages you would like to index. Once this is completed upload crawler.cgi into your hostings cgi-bin in ASCII mode. Set the chmod permissions to 755. Depending on your current server permissions you may also have to create a text file in the same directory called pages.txt and set the permissions to 666 or 777.
The Methodology
Create a database- Any database will work. I prefer sql but anything will work. A flat file is great because it can be used later on anything including Windows apps.
Specify the starting url you would like to crawl- In this instance the script will start at a domain. It can also index everything in a subpage as long as you don’t include the trailing slash.
Pull the starting page- I used the LWP simple module. It’s easy to use and easy to get started with if you have no prior experience.
Parse for all the links on the page- I use the HTML::LinkExtor module which is a submodule of LWP. It will take content from the lwp call and generate a list of all the links on the page. This includes links made on images.
Remove unwanted links- Be sure to remove any links it grabs that are unwanted. In this example i removed links to images, flash, javascript files, and css files. Also be sure to remove any links that don’t exist outside of the specified domain. Test and retest your results on this. There are many more you will find that will need to be removed before you actually start the scraping process. It is very site dependant.
Check your database for duplicates- Scan through your new links and make sure none already exist in your database. If they exist remove them.
Add the remaining links to your database- In this example I appended the links to the bottom of the text file.
Rinse and repeat- Move to the next page in your database and do the same thing. In this instance I used a while command to cycle through the text file till it reaches the end. When it finally reaches the end of the file the script is done and it can assume every crawlable page on the site has been accounted for.
This method is called the pyramid crawl. There are many different methods of crawling a website. Here’s a few to give you a good idea of your options.
Pyramid Crawl
It assumes the website flows outward in an expanding fashion like an upside down pyramid. It starts with the initial page which has links to pages 2,3,4 etc. Each one of those pages has more pages that they link to. They may also link back up the pyramid but they also link further down. From the starting point the pyramid crawl moves its way down until every building block on the pyramid doesn’t contain any unaccounted for links.
Block Crawl
This type of crawl assumes a website flows in levels and dubbs them as “stages.” It takes the first level (every link on the main page) and it creates an index for them. It then takes all the pages on level one and uses their links to create level 2. This continues until it has reached a specified number of levels. This is a much less thorough method of crawling but it accomplishes a very important task. Lets say you wanted to determine how deep your back link is buried into the site. You could use this method to say your link is located on level 3 or level 17 or whatever. You could use this information to determine your average link depth on all your site’s inbound links.
Linear Crawl
This method assumes a website flows in a set of linear links. You take the first link on the first page and crawl it. Then take the first link on that page and crawl it. You repeat this until you reach a stopping point. Then you take the second link on the first page and crawl it. In otherwords you work your way linearly through the website. This is also a not a very thorough process. It can be with a little work. For instance if you took the second link from the last page instead of the first on your second cycle and worked your way backwards. However this crawling also has its purpose. Lets say you wanted to determine how promenant your backlink was on a site. The sooner your linear crawl finds your link it can be assumed the more promenant the link is placed on the website.
Sitemap Crawl
This is exactly what it sounds like. You find their sitemap and crawl it. This is probably the quickest crawl method you can do.
Search Engine Crawl
Also very easy. You just crawl all the pages they have listed under the site: command in the search engine. This one has it’s obvious benefits.
Black Hatters: If you’re looking for a sneaky way to get by that pesky little duplicate content filter consider doing both the Pyramid Crawl and the Search Engine Crawl and then compare your results.
For those of you who are new to crawling you probably have a ton of questions about this. So feel free to ask them in the comments below and the other readers and I will be happy to answer them the best we can.
General Articles21 Nov 2006 02:14 am
Eli’s Social Experiment-What Type Of Internet Marketer Are You?
Oh boy lots of action has been going on in the recent How To Make A $100 per Day post. If you haven’t checked it out yet I strongly recommend you get that scroll wheel workin! We got a ton of responses and great some great ideas emerged from the brainstorming sessions. However I have to admit there was an alternative motive behind that post. Haha, com’n you know better than anyone that there’s no such thing as a carrot dangling in front of you without a string attached. Besides getting a good cash idea out there the main reason for the post was to help people identify what type of Internet marketer best describes them. I’m a firm believer that knowing your strong points and your weaknesses is the first step to producing solid money making projects. As you probably are starting to realize the project proposed wasn’t so cut and dry as it appeared. Infact it required a little bit of everything a good project has; Tough decisions, creativity, motivation issues, independent research, and good ol’ fashion moral delemmas. Facts be faced no matter what the project, if it’s going to make you money than inevitably you’re going to get confronted by each and every one of these elements at least once. The best way to prepare is to know where you stand on each one. Know your limits and know your potential.
Other blogs seem to talk a lot about this topic but since this is Blue Hat SEO I decided to go with a more creative approach and instead I attempted to give everyone actual hands on experience so they can learn first hand about problem solving with a real life example. As you’ll find out it doesn’t matter in the slightest if you even attempted the $100/day project. What matters is how well can you dissect your own though process when you originally read the post. This is why I said read the post at least three times; I wanted people to really put some serious thought into it.
Those of you who read the post realized instantly that you were hit with ambiguities and decisions you were going to have to make. How you made the decisions determined how the project turned out for you. Let’s step through the problems one by one starting from the beginning. Remember this was not a test so there were no wrong answers. So in the spirit of a social experiment. Take this short quiz and do your best to interpret and dissect your own thought process during all phases of the project.
(more…)
How to make a $100 per day
I just realized something! This entire blog is filled with ideas on how to help your sites make more money and receive more traffic, but I don’t have a single post that says, HEY! HERE IS HOW YOU MAKE MONEY. I want a post that tells you exactly how to reach your goals. A comment in another post (I do read them and get inspired by them) reminded me of this. So I perused through some old projects of mine and grabbed one thats very easy, very automated, reciprocal (consistantly makes money forever), and makes about a $100/day. Most of all it requires very minimal time and investment. So here ya go! Follow the instructions carefully and do as I did.
Here Is What You Do
1) Pick a generalized niche that is fairly popular. Celebrities work well, cars, animals. Anything will do.
2) Make a list of 300 items in that niche. For instance if you pick music artists make a list of the top 300 most popular music artists.
3) Download at least 20 public use(noncopyrighted) pictures of each item in your list.
4) Download or buy a screensaver maker. I don’t remember which one I use so I’ll have to update you in the comments when I get back to the office on Monday. Just make sure it is quick and easy to create the screensavers (saves you a lot of time) and comes with an exe output function that’ll easily install the screensavers on their computer without much dialog boxes or windows getting in thier way. This one looks decent. Easy Screensaver Maker and its only $25. Update: I use Screen Saver Builder. It’s $20 with fully functioning 21 day trial.
5) Create all your screensavers and put them up on a simple website. Give each screensaver its own page and download link. It also never hurts to SEO the site so it’ll do well in the search engines and make you even more money later on. Adsense also doesn’t hurt for a lil’ bit of extra cash.
6) Signup with Zangocash (Aff Link). This step is optional. See the comments for more ideas on how to monenize your new screensavers.
7) Talk to your account manager and ask him to bundle Zango software with your screensavers. Send him all the installers along with a textfile containing all the short descriptions and a sample picture. They are usually happy to do this for you. If they aren’t get a new account manager.
8) Get yourself a copy of Promosoft software submitter(nonAff link). I think it costs $95 for a copy but trust me it’s well worth it.
9) Follow the instructions on Promosoft to create the PAD files(product description files used for software sites) and submit each screensaver to hundreds of software and screensaver directories.
There you go. You will get paid $0.45 for every person who installs your screensaver. Once the screensavers are submitted you will have no problem getting tons of people downloading them everyday. If you get about 250 downloads per day(easy with 300 screensavers) you will easily make about a $100/day!
Okay so now all those people on forums and such who are bitching and moaning; saying stuff like “I want to quit my day job” and “I wish I could make a living online” can finally shut up. It is all right there, spelled out in plain english. You now have absolutely no excuses. Get off your ass and actually do it. Follow each step carefully and do a good job. It should take the average person no more than a couple days to get it done and you will make continuous money for a very long time. If you’re reading this and you suddenly realize that you are one of those people, just know that there is nothing wrong with that. We were all there. You just have to know when to quit. Quit searching forums for ideas. Quit buying ebooks hoping they’ll give that magical $100/day project idea. Quit asking “SEO experts” how they do it, and for God’s sake quit reading blogs hoping someone will post something like this, cus it just ain’t gonna happen(haha). All I expect from you is to read this post throughly and carefully at least two more times and actually follow through. There is nothing more I would love, than to hear someone tell me that an article I wrote helped them quit their job in the next 8 weeks. So make it happen!
Good Luck and Lets Get Back To Some SEO Shall We?
Update 3/20/07: The comments for this post are getting semi-ridiculous So a nice user has setup a forum especially for this post, where it can be discussed in a more efficient manner. Feel free to register.
http://www.zoomist.com/
Guides17 Nov 2006 06:46 am
Complete Guide To Scraping Pt. 1
In the spirit of releasing part four of my Wikipedia Links series we’re going to spend a couple posts delving into good ol’ black hat. Starting with of course; scraping. I’ve been getting a few questions lately about scraping and how to do it. So I might as well get it all out of the way, explain the whole damn thing, and maybe someone will hear something they can use. Lets start at the beginning.
What exactly is scraping?
Scraping is one of those necessary evils that is used simply because writing 20,000+ pages of quality content is a real bitch. So when you’re in need of tons of content really fast what better way of getting it than copying it from someone else. Teachers in school never imagined you’d be making a living copying other peoples work did they? The basic idea behind scraping is to grab content from other sources and store it in a database for use later. Those uses include but not limited to, putting up huge websites very quickly, updating old websites with new information, creating blogs, filling your spam sites with content, and filling multimedia pages with actual text. Text isn’t the only thing that can be scraped. Anything can be scraped: documents, images, videos, and anything else you could want for your website. Also, just about any source can be scraped. If you can view it or download it, chances are you can figure out a way to copy it. That my friend is what scraping is all about. Its easy, its fast and it works very very well. The potential is also limitless. For now lets begin with the basics and work our way into the advanced sector and eventually into actual usable code examples.
The goals behind scraping?
The ultimate goal behind scraping are the same as actually writing content.
1) Cleanliness- Filter out as much garbage and useless tags as possible. The must have goal behind a good scrape is to get the content clean and without any chunks of their templates or ads remaining in it.
2) Unique Content- The biggest money lies in finding and scraping content that doesn’t exist yet. Another alternative lies in finding content produced by small timers that aren’t even in the search engines and aren’t popular enough for anyone to even know the difference.
3) Quantity- More the better! This also qualifies as finding tons of sources for your content instead of just taking content from one single place. The key here is to integrate many different content sources together seamlessly.
4) Authoritive Content- Try to find content that has already proven itself to be not only search engine friendly but also actually useful to the visitors. Forget everything you’ve ever heard about black hat seo. Its not about providing a poor user experience, infact its exactly the opposite. Good content and user experience is what black hat strives for. It’s the ultimate goal. The rest is just sloppiness.
Where do I scrape?
There are basically four general sources that all scraping categorizes into.
1) Feeds- Real Simple Syndication feeds(RSS) are one of the easiest forms of content to scrape. Infact that is what RSS was designed for. Remember not all scraping is stealing, it has its very legitimate uses. RSS feeds give you a quick and easy way to separate out the real content from the templates and other junk that may stand in your way. They also provide useful information about the content such as the date, direct link, author and category. This helps in filtering out content you don’t want.
2) Page Scrapes- Page scrapes involve grabbing an entire page of a website. Than through a careful process, that I’ll go into further detail later, filter out the template and all the extra crap. Grab just the content and store it into your database.
3) Gophers- Other portions of the Internet that aren’t websites. This includes many places like IRC, newsgroups…..all hell here’s a list -> Hot New List of Places To Scrape
4) Offline- Sources and databases that aren’t online. As mentioned in the other post encyclopedias, dictionary files, and let us not forget user manuals.
How Is Scraping Performed?
Scraping is done through a set methodology.
1) Pulling- First you grab the other site and download all its content and text. In the future I will refer to this as an LWP call, because that is the CGI module that is used to perform the pull action.
2) Parsing- Parsing is nothing short of an art. It involves grabbing the page’s information (as an example) and removing everything that isn’t the actual content (the template and ads for instance).
3) Cleaning- Reformatting the content in preparation for your use. Make the content as clean as possible without any signs of the true source.
4) Storage- Any form of database will work. I prefer mysql or even flat files (text files).
5) Rewrite- This is the optional step. Sometimes if you’re scraping nonoriginal content it helps to perform some small necessary changes to make it appear as an original. You’ll learn soon enough that I don’t waste my time scraping content if it isn’t original (already in the engines) and focus most of my efforts on grabbing content that isn’t used on any pages that would already exist on search engines.
In the next couple posts in this series I’ll start delving into each scrape types and sources. i’ll even see about giving out some code and useful resources to help you a long the way. How many posts are going to be in this series? I really have no idea, its one of those poorly planned out posts that I enjoy doing. So I guess as many as are necessary. Likewise they’ll follow suite with the rest of my series and increasingly get better as the understanding and knowledge of the processes progresses. Expect this series to get very advanced. I may even give out a few secrets I never planned on sharing should I get a hair up my ass to do so.
Random Thoughts14 Nov 2006 05:53 am
Thank You Come Again
Heya everyone,
I was going to leave this in a comment but i decided it would be best put as a post. I just wanted to give a big thank you to everyone for all the help and support you gave me with the Quick Indexing Tool. Much to my surprise my first public SEO tool release went off without a hitch. I was honestly expecting the worse. Instead i got a huge very positive response (sorry I’m still trying to work my way through the emails). A lot of people gave me very useful feedback on it and likewise many are donating back. It was inevitable that an asshole or two would come out of the wood works and abuse the tool, but to my shock not a single one has. Everyone has used it very responsibly and its been working out great to everyones benefit. I also would like to thank everyone who sent me before and after screenshots of their spider stats. It was very helpful.
From the release I’ve chosen a 100 random sites to monitor closely and I have also been watching the emails from peoples personal experiences with the tool. Here is the general results I’ve managed to scrap together from a large majority of the data.
27% of sites were already in the index. This is fine. Even if they are already in the index go ahead and submit them anyways. It’ll help the rest of your site get indexed.
31% Made it into the index within 27 hours of running the tool. YAY!
22% Made it into Yahoo and MSN within 27 hours but didn’t make it into Google until 48 hours. Damn Google why you gotta mess with me like that
5% Didn’t make it into all three until 48 hours.
2% Didn’t make it into all three until 72 hours.
13% Never made it in to to all three. My optomistic thinking hopes that a large percentage the sites in this category were either already banned urls, or contain logistical problems. If your site falls into this category after 4 days email me or leave a comment and I’ll see what i can do to figure out why.
All in all the tool was, what I consider, a huge success. Both in the donations and the lack of abusers. I would also like to thank all the people that linked to the tool and/or shared it with others. For those of you who donated I can’t thank you enough. Whether you donated a $100 or one penny(yes i got one of those) it really shows that you care and just knowing that people actually care enough to do something about it makes this whole Blue Hat project definitely worth it.
SEO Tools10 Nov 2006 05:51 pm
QUIT- Quick Indexing Tool
Boy oh boy I finally get to release my first SEO Tool! Just in time to help make some people money for the holidays. As mentioned on my Merry Christmas post I’m excited because as a first tool I must set a standard for the quality of Blue Hat SEO tools. This tool definitely meets and exceeds any standards you can throw at it. Infact its downright bad frickin ass.
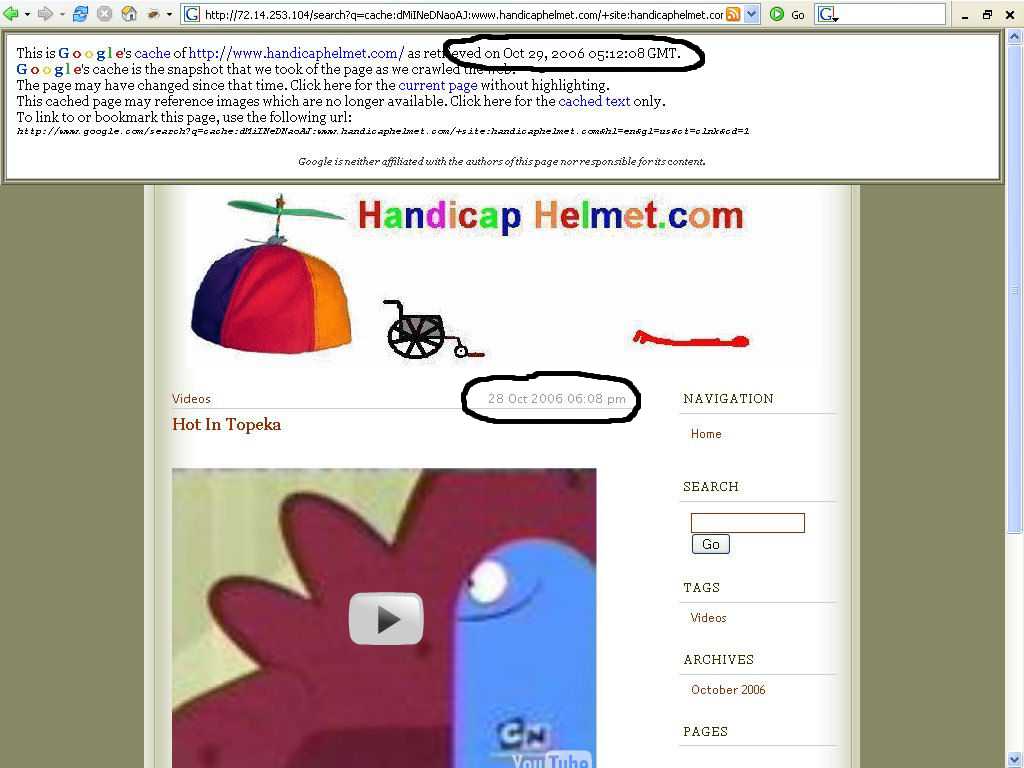
It’s called QU.I.T. Quick Indexing Tool. I had to slim a few features from the original but so far all tests have proven it is just as effective. Basically QUIT utilizes tons of techniques to get your site crawled and indexed VERY quickly. Don’t believe me? Check out my screenshot from a brand new little fun little blog I made for me and my friends called HandicapHelmet.com to post the stupid funny stuff we find or have to say.
Screenshot
Notice that it got indexed in less than 24 hours. I’ve tested this tool on 5 brand new sites so far and they all got indexed in less than 24 hours after running the tool. I’m not afraid to brag. Its results are down right impressive!
How Does It Work?
It does a few extremely secretive techniques which I am yet to dispell on this site, but for the most part I am happy to share.
1) Submits your site to 6 major social bookmarking sites. The only two its missing at the current moment is Yahoo and Del.icio.us because the server BlueHat is on is my “I don’t care, public” server and doesn’t have all the secure socket mods I need to include them. Not only does it submit your sites to the social bookmarking sites but it submits them several times through several different accounts. This instantly makes your site one of the most popular on the network which gives you extra linking power. Right now I have it limited to 2-5 accounts/social bookmarking site but I may up it if this tool generates a few kind donations.
2) Googlebot Slam- This combines the Blue Hat Technique #7 (which has become less effective over the months) with a very secretive technique that most people thought was impossible and I never plan on sharing. The concept is basically the same though. The best way to describe the technique is that it remotely tricks Googlebot into thinking that your site has fresh content and that it needs to rush over and check it out.
3) Global Ping- The script performs a multithreaded ping to all the major and minor blog ping sites. This has been proven to work well with getting your site indexed. Granted it has also become less effective over the last year, but when you combine it with the rest of the techniques this script utilizes it works very well.
4) Various others- about four other techniques that I will probably never mention until I am ready to retire them out to the community. BTW. For those of you who are curious, the script never actually pulls your site or anything of that nature, so you don’t have to waste your time trying to find something in your logs that will give away these secrets. Sorry, theres just some stuff I have to keep to myself :) Until then enjoy being able to use them.
The Script
Fill out this short form. Hit the button and you’re done! It’s just that easy. Be sure not to hit the button more than once. It will take a minute or two for the script to complete(depending on current workload from other users).
CLICK HERE TO DONATE TO THIS TOOL
Keep This Script Alive By Donating
Like I mentioned this script isn’t on a badass server or anything. Also, BlueHatSEO isn’t a for profit site. So if you would like to keep this script alive and running please make a donation. I suggest donating based upon your usage of the script. The more you use the more you should consider donating. My formula for the donations is really simple. However much you feel like donating is definitely appreciated. Don’t break your bank on me but please consider donating at least something.
1) If the script causes the usability and speed of the site to dramatically drop and the donations are too low. I take the script down
2) If the script causes the usability and speed of the site to dramatically drop and the donations are high. I’ll move BlueHatSEO to its own powerful server and even build some new tools.
3) If the script really doesn’t cripple anything than I’ll let it be.
The Rules
1) For the moment I am going to allow people to use the script automatically and leave it open to LWP calls. Just point your scripts to https://www.bluehatseo.com/cgi-bin/quit.cgi?path=go&title=$title&url=$url&category=$category&comments=$comments&clipping=$clipping&email=$email
For the email please use the email address you used to donate to the script. So I can track how many leechers I have.
2) Don’t use the script more than once every five minutes. You abuse it you loose it
3) Don’t use the script more than once per site. There really is no need to.
Enjoy!
ps. I would love to hear some feedback on this script. Let me know how it worked for you. Also, when I get some time I’ll code in a stats tracking subroutine for it. So everytime someone submits a site through the tool it keeps track of when the tool first ran and when the site made it into the index. Then have it make a global average for all of us to know. That would be pretty useful. Also, I got tons of ideas for tools to put up on this site. It is just a matter of getting around to actually making them or finishing them. If you have any ideas of tools no one else would dare make let me know.
Random Thoughts07 Nov 2006 06:40 am
Happy Early Christmas!
I got a present for ya’ll coming very soon! I’m so excited. Are you excited?
Will it be a bike? Will it be a new puppy? Only time will tell…
— Next Page »

{kind=link}