June 2007
Monthly Archive
Black Hole SEO18 Jun 2007 09:53 pm
Black Hole SEO: The Real Desert Scraping
Alright fine. I’m going to call uncle on this one. With my last Black Hole SEO post I talked about Desert Scraping. Now understand, I usually change up my techniques and remove a spin or two before I make them public as to not hurt my own use of it. However on this one, in the process, I totally dumbed it down. Upon retrospect it definitely doesn’t qualify as a Black Hole SEO technique, more like a general article, and yet no one called me on it! Com’n guys you’re starting to slip.  Enough of this common sense shit, lets do some real black hat. So the deal is I’m going to talk about desert scraping one more time and this time just be perfectly candid and disclose the actual spin I use on the technique.
Enough of this common sense shit, lets do some real black hat. So the deal is I’m going to talk about desert scraping one more time and this time just be perfectly candid and disclose the actual spin I use on the technique.
The Real Way To Desert Scrape
1. Buy a domain name and setup Catch-All subdomains on it using Mod-Rewrite and the Apache config.
2. Write a simple script where you can pull content from a database and spit it out on it’s own subdomain. No general template required.
3. Setup a main page on the domain that points links to the newest subdomains along with their titles to help them get indexed.
4. Signup for a service that monitors expiring domains such as DeletedDomains.com (just a suggested one, there’s plenty much better ones out there).
5. On a cronjob everyday have it scan the newest list of domains that were deleted that day. Store the list in a temporary table in the database.
6. On a second cronjob continuously ran throughout the day have it lookup each expired domain using Archive.org. have it do a deep crawl and replace any links to their local equivalents (ie. www.expireddomain.com/page2.html becomes /page2.html). Do the same with the images used in the template.
7. Create a simple algorithm to replace all known ads you can find and think of with your own, such as Adsense. Also it doesn’t hurt to replace any outgoing links with other sites of yours that are in need of some link popularity.
8. Put the scraped site up on a subdomain using the old domain minus the tld. So if the site was mortgageloans.com your subdomain would be mortgageloans.mydomain.com.
9. Have the cronjob add the new subdomain up on the list of completed ones so it can be listed on the main page and indexed.
What Did This Do?
Now you got a site that grows in unique content and niche coverage. Everyday new content goes up and new niches are created on that domain. By the time each subdomain gets fully indexed much of the old pages on the expired domains will start falling from the index. Ideally you’ll create a near perfect replacement with very little duplicate content problems. Over time your site will start to get huge and start drawing BIG ad revenue. So all you have to do is start creating more of these sites. Since there are easily in the six figures of domains expiring everyday that is obviously too much content for any single domain, so building these sites in a network is almost required. So be sure to preplan the load possible balancing during your coding. The fewer scraped sites each domain has to put up a day the better chances of it all getting properly indexed and ranking.
And THAT is how you Desert Scrape the Eli way.
*Wink* I may just have hinted at an unique Black Hole SEO way of finding high profit and easy to conquer niches. How about exploiting natural traffic demand generated by article branding?
Black Hole SEO16 Jun 2007 02:00 pm
Black Hole SEO: Desert Scraping
In my introduction post to Black Hole SEO I hinted that I was going to talk about how to get “unique authoritative content.” I realize that sounds like an oxymoron. If content is authoritative than that means it must be proven to work well in the search engines. Yet if the content is unique than it can’t exist in the search engines. Kind of a nasty catch-22. So how is unique authoritative content even possible? Well to put it simply, content can be dropped from the search engines’ index.
That struck a cord didn’t it? So if content can be in the search engines one day and be performing very well and months to years down the road no longer be listed, than all we have to do is find it and snag it up. That makes it both authoritative and as of the current moment, unique as well. This is called Desert Scraping because you find deserted and abandoned content and claim it as your own. Well, there’s quite a few ways of doing it of course. Most of which is not only easy to do but can be done manually by hand so they don’t even require any special scripting. Let’s run through a few of my favorites.
Archive.org
Alexa’s Archive.org is one of the absolute best spots to find abandoned content. You can look up any old authoritative articles site and literally find thousands of articles that once performed in the top class yet no longer exist in the engines now. Let’s take into example one of the great classic authority sites, Looksmart.
1. Go to Archive.org and search for the authority site you’re wanting to scrape.
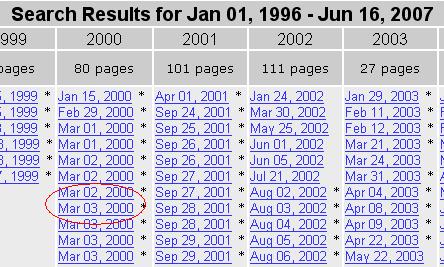
2. Select an old date, so the articles will have plenty of time to disappear from the engines.
3. Browse through a few subpages till you find an article on your subject that you would like to have on your site.
4. Find an article that fits your subject perfectly.
5. Do a SITE: command in the search engines to see if the article still exists there.

6. If it no longer exists just copy the article and stake your claim.

See how easy it is? This can be done for just about any old authority site. As you can imagine there’s quite a bit of content out there that is open for hunting. Just remember to focus on articles on sites that performed very well in the past, that ensures a much higher possibility of it performing well now. However, let’s say we wanted to do this on a mass scale without Archive.org. We already know that the search engines don’t index each and every page no matter how big the site is. So all we have to do is find a sitemap.
Sitemaps
If you can locate a sitemap than you can easily make a list of all the pages on a domain. If you can get all the pages on the domain and compare them to the SITE: command in the search engines than you can return a list of all the pages/articles that aren’t indexed.
1. Locate the sitemap on the domain and parse it into a flat file with just the urls.
2. Make a quick script to go through the list and do a SITE: command for each URL in the search engines.
3. Anytime the search engine returns a result total of greater than 0, just delete the url off the list.
4. Verify the list by making sure that each url actually does exist and consists of articles you would like to use.
There is one inherent problem with the automatic way. Since it’s grabbing the entire site through its sitemap than you are going to get a ton of negative results, like search queries and other stuff they want indexed but you want no part of. So it’s best to target a particular subdirectory or subdomain within the main domain that fits your targeted subject matter. For instance if you were wanting articles on Automotive, than only use the portion of the sitemap that contains domain.com/autos or autos.domain.com.
There are quite a few other methods of finding deserted content. For instance many big sites use custom 404 error pages. A nice exploit is to do site:domain.com “Sorry this page cannot be found” then lookup the cached copy in another search engine that may not of updated the page yet. There is certainly no shortage of them. Can you think of any others?
Cheers
General Articles13 Jun 2007 07:41 pm
How To Build Your Own SQUIRT
LOL, be truthful. Did you honestly see this post coming? People wanted to know how the tool works, but I think I can do you all one better. I’ll explain in detail how exactly it works and how to build one for yourself so you can have your very own, hell one to sell if you wanted. Would you guess there’s a demand for one? Haha Sure why not? I can’t think of a single good reason why I shouldn’t (I never considered money a good enough reason to not help people). However I would like to ask a small favor of you first. Please go to RobsTool.com and subscribe. Throughout this month we are adding a new section called “The Lab” inside the tool where we are going to be hosting a multitude of crazy and wacky SEO tools that you’ve probably never thought could exist. Even if you don’t have a membership please subscribe anyways so you can get some cool ideas for tools to build yourself. That out of the way, lets begin.
The Premise
SQUIRT works off of a very, very simple premise. Over the span of the months you promote your websites from their infancy to well aged mongers, you make dozens of small decisions daily. All the tool does is mimic as many of those decisions as possible and boil them down to a small yes or no; true or false; boolean expression. This is just very basic AI (Artificial Intelligence) and decision making based on some data. There really is nothing complex about it. Think about the first time you promoted a website in the search engines. You looked at what you considered some factors in ranking. You saw what your competitors had that you didn’t. What was your first initial reaction? You likely thought, “how can I get what they have?” A script can’t do this of course. This is a human reaction that can’t be duplicated by a machine. However, now think about the second, fifth, tenth website you’ve promoted. Once again you looked at what your competitors had that you didn’t. From there you may have noticed your mindset changed from “how can I get it” to something like, “how did I get it before?” This a machine can do! Experience just made the difference between a decision that needs to be made and a predefined decision that sets an orchestrated path. I know this all seems overwhelming, but I assure you its all really, really simple. The trick is, just build a tool that would do whatever you would do, based on the current situation. The situation of course can be defined by what we all know and study everyday of our professional SEM lives, Search Engine Factors. So the best place to begin is there.
A List Of Factors
Since the tool will make its decisions based on stuff you consider to be factors search engines use to rank your sites, making a list of all the known factors is a big help. Sit and write down every search engine factor you can think of. Break them down to specifics. Don’t just write “links.” Write Link Volume, Link quality, links on unique domains, percentage of links with my anchor text..etc. The SQUIRT utility I released looks at 60 separate factors. So at least you have a general goal to shoot for. Come up with as many factors as possible. Once you got a good clean list of factors start figuring out a proper way to measure each of them.
Factor Measurement
How many times today did you go to a search engine and type in link:www.domain.com? That is a measure of a factor. How about site:www.domain.com? Thats another. Each of those are a factor that when explored by either going to your own site, or going to the search engines can result in some sort of figure or number you can use to calculate how your site fairs in comparison to the sites currently ranking. Let’s use an example. You go to google and you search for your keywords that you are wanting to rank for. You make a list of all the sites in the top 10 and separately do a link: command for each of their domains. You then take all those figures and average them out. That gives you a rough idea of how much “link volume” you will need to get into the top 10. You then do a link: command on your own site to see how close your site is to that figure. From there you can make a decision. Do I need to work on increasing my link volume factor or not? You just made a boolean decision based on a single factor using data available to you. It probably took you a good 5 minutes or more to make that decision. Where as a script could of made that decision for you in less than a second. Now I know you’re all just as much of a computer nerd as I am, so I don’t have to preach to you about the differences in efficiency between yourself and a machine, but at least think about the time you would compound making these very simple decisions for each and every factor on your list for each site you own. There goes a good five hours of your work day just making the predictable yes or no decisions on what needs to be done. This sounds ridiculous of course, but I’d be willing to bet that at least 90% of the people reading this post right now spend most of their time doing just that. Ever wonder why most search marketers just trudge along and can’t seem to get anywhere? Now you know.
Making The Decisions
Okay so let’s take an example of a factor and have our script make a decision based on it. We’ll look at the anchor text saturation factor. We look at our inbound links and find all the ones that contain our anchor text versus the ones that don’t and only contain some similar words somewhere else on the page(most other documents). We then make a percentage. So we’ll say after looking at it 30% of our inbound links contain our exact anchor text. We then look at our competition. They seem to average 40%. Therefore our script needs to follow a promotional plan that increases our percentage of links that contain our exact anchor text. Very good, we’ll move along. Next we’ll look at inbound links that don’t contain our anchor text but contain our keywords somewhere in the document. Looking at our site we seem to average about 70%. Our competition seems to average about 60%. So we are doing much better than our competition. Therefore our script doesn’t need to increase our links that doesn’t contain our exact anchor text but do have relevant text. Wait, did I just contradict myself? These two factors are complimentary. So the more our tool increases one factor the further the other one drops. Wouldn’t this throw our promotion through some sort of infinite loop? Yes I did contradict myself and Yes it would put our promotion through an infinite loop. This is called on going promotion. The fact is THEY rank YOU don’t. Therefore you have to keep improving the factors you lack until you do rank; even if they seem to almost contradict each other. By the end of the analysis your script ends up with a long list of DO’s and a long list of DON’T NEED AT THIS TIME. So now all you have to do is use your own experience and your own site network to make all the DOs happen to the best of it’s abilities.
Establishing A Promotional Plan
So now that we have a list of all the stuff we need to improve with our site we can program our SQUIRT script to just simply do whatever it is we would do to compensate for our site’s shortfalls. To give you a better idea of how to do this and how SQUIRT handles these exact situations, I’ll take 3 example factors and let you know exactly what it does when you hit that submit button. However keep in mind, no matter how much information you gather on each site, every promotional situation is unique and requires a certain amount of human touch. The only thing you can do is define what you would do in the situation if you had no prior knowledge of the site or any extenuating circumstances. Also keep in mind that you have to remain completely hands off. You don’t have ftp access to their site, you can’t mess with their design. So anything you do has to be completely offsite SEO. Also, anything you do can’t hurt the site in anyway. Every plan needs to be 100% focused on building, and any method of promotion that may possibly cause problems for them, even if you plan on only running throw away black hat sites through the tool, needs to be 100% positive. So if you want to go get links. You need to do it within your own network of sites. You can’t go out sending spam comments or anything.
Page Rank
Your Site: PR 2
AVG Competitor: PR 3
Decision: Increase Page Rank
The Plan: Create a network of very large sites. Since pagerank can be gathered internally just as easily as from external sources. Than you need to build a network of sites with lots and lots of indexed pages. Take a look at the current volume of sites you plan on running through your SQUIRT tool and decide how big you need to build your network before hand. When we decided to make SQUIRT public, even though not all the sites would require a Page Rank increase we knew a TON would. We launched the tool with the capability of handling 500 members. So we knew that 500 members, submitting 10 sites/day with each link needing to hold on a single page for at least a week, could result in needing 150,000 links available to us each week. If each link was on a page with a PR 1 than each page would send a tiny page rank increase to the target link. Likewise if each indexed page had a PR1 and we put five links up on each page, than each page would give out even more page rank through the links. There is a point of saturation of course. We decided 10 was good for each page. So we could get the maximum amount of pagerank sucked out of each indexed page while maintaining the highest possible volume of links we could spare. So if we built a network of sites that contained a total of about 1,000,000 pages indexed(you heard me), each averaging a PR1. Than we could transfer enough page rank to 150,000 links/week to constitute a possible bump in page rank to each link. For your own personal SQUIRT of course you don’t need nearly that volume. However make sure to preplan ahead because even if you make a 1 million page site, it doesn’t mean you will get 1 million pages in the index. So may have to build quite a few very large sites to reach your goals. This of course takes time and lots of resources.
Anchor Text
Your Site: 30%
AVG Competitor: 40%
Decision: We need to increase the number of links that contain our exact anchor text.
The Plan: Now since the tool can’t directly affect the site than we can’t exactly go to every inbound link the site has gotten and figure out a way to get them to change the anchor text. There are just too many ways to gain links and its completely unreasonable to attempt. So the only way to increase the anchor text match percentage is to increase the total number of links to the site and then have them all match the anchor text. This is where you need to queue up the blogs. All you have to do is create a bunch of blogs all over, and take steps to increase the chances of each individual post getting indexed. Than you can fill the blogs with the anchor text of the site. This however is no easy task when dealing with a large volume. Since you need plenty of authority you will need to get accounts on all the major blog networks. Remember, the average blog usually has less than 5 posts/day so you will need to compensate in sheer volume of actual accounts. These will also need to be maintained and anytime one gets banned another needs to be automatically created to take it’s place. Those of you using the tool have probably already noticed links from these places showing up in your logs and Technorati links. Since we knew so many links/day would be required we had to create an absolutely HUGE network of blogs on various places as well as the automated system to create new ones if another gets buried. Once these links have been dispersed over time, the anchor text percentage will start to rise.
Deep Indexing
Your site: 3 pages in the index.
Crawl Stats: 10+ subpages identified
Decision: Need to get more bots to the subpages of the submitted site.
The Plan: So the script grabs the main page of the site and immediately sees more subpages available than are currently indexed in the search engines. This lets us know that the submitted site is having a hard time being properly deep indexed. So this is when we queue the Roll Over Sites to help get some SE bots to these subpages. There is one problem however. When dealing with my own sites it’s fine to scrape the content then redirect as detailed in the strategy that I talked about in the Power Indexing post. However since this tool will be a public one I can’t scrape peoples content because there is the odd chance that my rollover site may temporarily outrank their actual site and it could draw some anger from people who don’t know what it is. Remember the rule. The tool can’t harm the site in any way. So we had to go another route. Instead we pulled from a huge list of articles and just used that as the content then pushed the spiders to those pages then when they got indexed, redirected them to the site. These of course don’t show up as links so it’s all backend, however it does a fantastic job of getting subpages indexed. Since Rollover Sites use actual content than there is no problem making them absolutely huge. Therefore you don’t need a very large network of them to push a very large amount of bots. Yet at the same time you still have to follow the rule of no interference with their site. So if their site is having a hard time getting deep indexed and you can’t exactly ftp a sitemap over than you have to bring in a large network of Third Party Rolling Sitemaps. So what you do is, you create a network of sites that are essentially nothing more than generic sitemaps. You drive a lot of bot traffic to them on a regular basis and have them roll through pages that go through the tool. Once the tool has identified up to 10 subpages of the target site than it can add them to the network of third party sitemaps. The new pages go in, old pages go out(The technical term for this is a FIFO algorithm). If you have a solid enough network of third party sitemaps you can hopefully push enough search engine crawlers through them to get every page crawled before it gets pushed out. This of course is a huge problem when dealing with a large volume of sites. If we originally wanted enough power for 500 members than we knew that 500 members submitting 10 sites/day which each contained up to 10 subpages would mean we would need enough third party sitemaps to accommodate 50,000 pages/day. While the efficiency of a single third party sitemap site may be big, a massive network would be needed to push that kind of volume. It’s just beyond unreasonable. So instead, we incorporated a gapping system. So anytime there wasn’t a new page coming in and it had a chance to display a set of links to a SE bot for the second time than it would grab some older entries that were already rolled through and display them as well. So if you push enough crawl traffic through than eventually every page will theoretically get crawled.
Rinse and Repeat
So thats all there is to it. It’s really quite simple. As you build your SQUIRT work your way through every factor you wrote down and think about what you would do as a hands off Internet Marketer to compensate if a site didn’t meet the requirements for that particular factor. This also applies to flaws in onsite SEO. Let’s say for instance the page doesn’t have the keywords in the title tag. You can’t touch that title tag, so whats the offsite SEO equivalent to not having the keywords in the title tag? Putting them in the anchor text of course. Just keep relentlessly plugging away and build an established plan for each factor on your list. With each failure to meet a factor there is potentially a problem. With each problem there is a potential solution your script and personal site network can take care of for you. It just may require a bit of thinking and a whole lot of building. It’s tough, trust me I know but it’s worth it because in the end you end up with a tool that comes close to automatically solving most of the daily problems that plague you. Here’s the exciting part. Once you start building and going through all the factors you’ll find some you probably can’t solve. Just remember, every problem has a solution. So you may just learn a few tricks and secrets of your own along the way. Shhh don’t share them.
Is SQUIRT Biased?
ABSOLUTELY! Think about what it uses to determine the site’s standing on it’s strengths and weaknesses. If you do a link: command there is a delay in time between what the search engine shows and what actually exists that may range up to days and weeks. This causes major problems. The tool may think you need a bunch of links when it in fact you already got plenty and they just haven’t shown up yet. It may think you have a ton of links when those links were actually only temporary or you lost them before they had a chance to disappear. Essentially the tool operates off of your site’s potential SEO worth. So lets say you have an old site that you haven’t really done anything with, then you run it through your SQUIRT. The tool will stand a much better chance of making an accurate analysis, and likewise any boosts you receive in the factors will more than likely be the right ones. Therefore it will appear as if your site just skyrocketed up simply because of one little submit through the tool. When in fact the site had that sort of potential energy the whole time and it just needed a little shove to get moving. The same could be said about an established site experiencing extremely slow growth. It fairs well, maybe even in the 60%+ range, so it appears to not need very much. Then at the same time, everything the tool does do, matters very little in the large scheme of your escalated promotional campaign. Also, the tool can only focus on one site during one phase in it’s promotion at a time. So if you got a brand new site that you submit, than the tool will naturally focus more heavily on getting the site properly indexed and less on helping it gain rank through the SERPS. So if indexing methodologies don’t completely work in that particular case than it appears as if your tool didn’t do anything at all. Remember, this is only a tool, its all artificial decision making. There is no substitution for the human touch. No matter how complex or how efficient a tool you build is, there is no way it can compete without an actual human element helping to push it. All your competitors are humans. So there’s no logical reason why you can expect to ever build a tool that is the end all solution to beating them everytime. So even though you now have a really cool tool, still remember to be hardworking, smart, and efficient…never lazy.
Sorry about the long as hell post, but you guys wanted to know what the tool was doing when you clicked the button. Now you do, and hey…least I didn’t go through ALL 60 factors.
Get Building
Announcements11 Jun 2007 12:54 pm
Back To The SEO
Thanks guys/gals sooooo much. This launch went crazy good. In fact it was downright record setting.
We almost double sold out in 2mins 21 seconds. We managed to stop the registrations at about 250 members(The tool can easily handle more than that). The server looks great, even though it underwent what can easily be considered a digg effect X5. Thanks to everyone who sent in reports of anything not working. We fixed them all and a few minor changes will be made to make sure everything is in perfect working order.
Couple things:
The domain errors was a result of not being able to find the whois information for a domain. This was fixed but some bugs may possibly remain with .co.uk and .c* domains until further notice.
Most of the accounts have been activated and been made to full member status. If your account isn’t activated by tomorrow please send an email to rob [at] robstool.com with your account email and paypal email information.
If you accidentally double paid through paypal, just email rob [at] robstool.com and let us know your account email and paypal email and we’ll make sure your account gets activated and properly credited.
The analysis tool is 100% free and uses no credits. So go ahead and use it at will, if you don’t have a subscription just create a guest account and you will still be able to use it.
The bunny in the logo is my real life bunny named Roady. He’s a 4lb fully grown 5 month old dwarf rabbit. He is potty trained, loves people, and makes the best mascot ever.
If You Missed The Registration
Send a blank email to waiting [at] robstool.com. This will automatically add you to the waiting list. Then as slots open up we will systematically move through the list on a first come first serve basis and give out invites to those next in line.
I’m always open to constructive criticisms. If you have any suggestions or feature requests definitely let me know. Any ideas to make this subscription gain value month to month is more than welcome.
Also, many people want a private forum here. This is being moled over however most of you already know that I am adamantly against people paying for SEO information. However, this place has a huge amount of very very smart readers, and I think a place where the readers here
can network with each other and share ideas privately would be great. So in the next couple days I will be opening a chatroom up. It’d also be really nice to meet some of you and get to talk to you outside of email.
Thanks so much and enjoy,
Eli
PS. Sorry for the long string of announcements. Lets get back to some SEO shall we?
Upcoming Changes
Announcements11 Jun 2007 07:59 am
Let’s Do This
Alright let’s get this over with
SQUIRT Is Now Open
squirt.robstool.com
Please be sure to register using the same email address as is on your Paypal Account.
Once you have registered and subscribed your account will be activated shortly and you will be notified by Email. If your account isn’t activated by the end of the day please send an email to Eli at BlueHatSEO.com with your Paypal email address and Email address on your account.
Good Luck
Announcements10 Jun 2007 10:00 am
T-Minus 22 Hours
This is kind of exciting
The tool will be released in 22 hours. I will post up the url to it here at exactly 9am PST(United States) Monday Morning.
Time Zones
9am US-Canada/PACIFIC
10am US-Canada/MOUNTAIN
11am US-Canada/CENTRAL
12pm US-Canada/EASTERN
6am US/Hawaii
6pm EUR/Germany
5pm EUR/London
Oh and I got a little surprise for you guys
After you register and login, check out the Vault inside your account. I posted up a badass commercial trackback spammer I made almost a year ago and chickened out of making it public (you’ll find out why once you try it).
But, screw it, you can have it for free. I’m too excited about this launch to even care.
Tomorrow is the day we show the industry what real tools are
PS. Fair warning. The subscriptions will require a Paypal account. So if you don’t already have one with a credit card attached, it wouldn’t be a bad idea to set that up in advanced.
PPS. The Vault currently has 36 databases and the one script. I think this will more than suffice for grand opening. However I plan on putting some hardcore work into this week and absolutely flood it with content.
Announcements06 Jun 2007 04:00 pm
A Few Quick Announcements
I got a few quick announcements to get out of the way if you don’t mind.
You’ve probably noticed that even though this blog is over a year and a half old I haven’t done any montenization on it. I’m not personally against the idea of it (I am an Internet marketer after all) but I’ve been holding out for a really good idea of how exactly to do it. I don’t want to just throw up some banners or become super lame by getting people to signup through my Algco account (kidding! I don’t do MLM schemes). I also would NEVER dream of putting the information here on a paid model. I want to monotenize it in a way that directly makes people money and helps them become more successful. That’s obviously easier pitched than done. But I think I came up with a good solution of how to do it.
Since the release of the Quick Indexing Tool I’ve gotten a lot of requests from people to buy access to my own personal tools. I’m really happy with the way QUIT turned out. It’s been thoroughly put through the ringer by over 50 bloggers and popular forums as well as thousands of readers here and has more than proven itself. It has finally been PROVEN to the industry that not only is it possible to get indexed in less than 24 hours but it can be done as easily as filling out a very short four part form and clicking a button. The concept actually goes one step further than that. Rankings can be just as easily acquired and admittedly for my own ego’s sake I want to prove to the industry that not only is it possible but anyone can do it.
So Here’s What’s Going To Happen
Sometime within a week I will be releasing a subscription based access to a version of my own personal toolset. The subscription will cost $100/month (canceling will be allowed anytime and none of your personalized data on your account will be deleted).
Here’s what the subscribers will get
1. SQUIRT- Super Quick Indexing and Ranking Tool.
A. Does everything QUIT does but even more efficiently, also includes a ton of extra social bookmarking sites. Including the virgin ones that no tools as of yet has the skills to automate submissions to.
B. Gets your site deep indexed faster. So not only will your main page go in faster but the rest of your site will get indexed faster and more efficiently.
C. Utilizes many of the techniques talked about here automatically. This includes Rollover sites, third party sitemaps, keyword real estate and several others that I haven’t even talked about yet. NONE of which can possibly get you banned or penalized. You are perfectly safe using this tool.
D. Deep analysis of your site. The tool looks at every possible ranking factor you can think of; including both onsite and offsite. It then rates your site on a percentage scale. 100% of course being the perfect site with perfect existing promotion(none exist that i’ve managed to find yet) and 1% being essentially brand new site with no promotion and horrible onsite factors. The analysis tool is an exact clone of the same one I use. It is all 100% custom and I use it everyday to analyze my sites as well as my competitions. As far as SEO analysis tools go it’s about as accurate as it gets.
E. Custom promotion. After analyzing your site and current levels of promotion the tool determines your weaknesses and strong points and automatically determines the perfect promotional campaign you will need to reach the top 10. There are literally thousands of different combinations the tool can go from there to determine the absolute perfect path to success for any given site. Can you guess what it does with this information?
F. It promotes your site. It uses it’s analysis to determine what techniques are needed to get you ranking in the top 10 and it automatically does them. The whole process from the time you fill out the two part form (URL and up to 3 keywords/phrases you are wanting to rank for) takes less than 3 minutes to run. So in other words you can build a site and have it promoted perfectly and precisely within a couple minutes. Sorry skeptics, there’s no B.S. here
2. X amount of submissions/day will be allowed
A. You will be allowed so many submissions a day through the tool. We haven’t quite worked out what the numbers will be yet, but they will be more than ample for the high producing webmaster, and at the same time low enough so the tool doesn’t get overly saturated.
B. I’m only going to allow 100 members. With the obvious power behind the tool I can’t let every Joe Schmoe play around with it. As neat as this tool is, it is definitely no toy and the use of it needs to be taken seriously. Which is why I’m giving you guys the first heads up. I know once I release it several large forums and blogs will catch wind, and while thats all fair I am personally biased with the Blue Hat readers. So I’m letting everyone here know in advanced. So if you’re interested in joining, be on the look out and if this site isn’t already in your reader or live bookmarks be sure to add it, because idealy I want you guys to have the first crack at it. Than if there are any extra slots others are welcome to it. This tool is for you after all not them.
3. Access to my personal content club
A. I’m going to be throwing up a HUGE collection of custom databases and scripts for you to download and use at will. They will all be free with the subscription. After all, what good is a tool that helps you mass promote a ton of sites quickly if you can’t easily produce sites just as quickly and easily. So I really want to help people build their networks and become more powerful in their markets. I think a private content club will be the perfect way to do that.
B. I also am cutting a deal with a good friend of mine (and avid reader here) to continually produce databases. He is incredibly talented at collecting high quality data and he sells his databases for big bucks. However since he’s a reader and commenter here he’s been cool enough to join in and help everyone out. So we’ll see what kind of deal we can cut so he can get paid for his work while at the same time getting to help you guys out with more quality data than you can handle.
4. Discounts on Blue Hat Tools.
A. A lot of posts here require custom coding. I’ve always encouraged programmers to join in and code my techniques for the readers here and sell them through the comments. I think thats a great way to not only reward the people who create the scripts and share them but to help the nontechnical people get their hands on the tools and scripts they wouldn’t be able to any other way. However there have been several large unforeseen problems this has caused. I have no idea who is trying to rip off my readers and who is legit. grrr.  So this way I’m going to team up with my own personal highly talented programmers and giving them heads up on all my upcoming posts that require custom scripts made. So when the techniques get posted here, you can log into your account and buy the script for a hugely discounted price.
So this way I’m going to team up with my own personal highly talented programmers and giving them heads up on all my upcoming posts that require custom scripts made. So when the techniques get posted here, you can log into your account and buy the script for a hugely discounted price.
What To Expect As Far As Ranking Capabilities
The tool is designed to rank a site within the top 10 for most medium and small sized niches. All the promotion in the world of course can’t rank a poorly designed site so that part is of course left up to you. However with adequate onsite SEO the tool by itself should be able to perform quite well within most medium sized niches alone. I also encourage everyone to test that for themselves.
So there you go. If you’re interested, keep your head up. It’ll be coming within about a week or less. I’ll post it here first and it’ll be hosted on a another server of mine as well as the blog of my business partner(an awesome programmer). I’ll be honest, I’m kind of scared of selling out and I’m even more scared of hyping something and having it not turn out to be as great as people were hoping. So please feel free to help me out with this. I really want to hear your opinions and ideas of what you would like to see to make this tool/club be of even more value to you. I want the $100/month to be pennies compared to what people actually get, so anything you can think of to make it even more badass let me know.
Thanks,
Eli
Guides03 Jun 2007 08:45 pm
How To Be A Gray Hat
Gray Hat SEO. Gray Hat SEO. Gray Hat SEO. I’m not keyword stuffing, I’m thinking. If gray hat is so widely accepted as a popular tactic than why are there no good articles on what it is and how to do it? Maybe, and this is just one theory, its fuckin’ impossible to write about. It’s just too damn much of a gray area in the industry (pun intended). Well, we’ll see about that.
So what exactly is Gray Hat SEO? Most define it as a site that uses questionable tactics? I think thats an excellent analysis, because the number one rule to gray hat is to be questionable. In fact the more you can get a trained eye to scratch their head wondering if your site is black hat or white the better. If you can fool the average visitor than you more than likely will fool a SE bot. In my opinion the best way to do this is to have an innate eye for structure.
In designing a structure for your gray hat site the best way to go about it is to steal a structure from a site that couldn’t possibly be banned. Let’s take Digg.com for example. Digg is setup in various primary categories where each contains news related stories. Each news story consists of a title with the link to the original article and a small, 255 character or so description. Each news story is accompanied by some user contributed content. Upon a indifferent perspective this is a very questionable structure. The content itself is very short and aren’t organized like a standardized article would be, the user contributed content is always very short and dispersed. Not to mention there is an enlarged lack of control over length of and quality of the user contributed “comments.” However the structure gives us some possibilities. We know that since Digg, Reddit and other social sites of the likeness are authoritative and standardized in the industry than naturally the search engine antispam algorithms couldn’t possibly automatically consider it of bad taste or a possibility of being considered a black hat site. This gives us a huge opportunity for a possible gray hat site.
Okay so the next step would logically be to figure out our content sources. Sticking with the Digg.com example we know that they get their content sources from large and small news related stories, mostly technology but that can excused for whatever niche we decide to target. This is a great place to start because Google has already been quoted as saying news related stories can’t be counted as duplicate content because they are so widely syndicated. It only makes sense. So getting news stories are easy. In fact it can be done by scraping lots of popular news RSS feeds. If we’re attempting to duplicate the Digg structure than we don’t need the entire articles despite what we’ve come to believe about SEO. We only need the partial story along with a title and then pad it with some user contributed content.
Where are we going to get some user contributed content? In this particular example I can’t think of a better place than the place we’re ripping off the structure from. We might as well pad each article with scraped user comments from Digg itself. So we can take the titles of each news piece and remove all the common words such as: “why”,”but”,”I”,”a”,”about”,”an”,”are”,”as”,”at”,”be”,”by”,”com”,”de”,”en”,”for”,”from”,”how”,”in”,”is”,”it”,”la”,”of”,”on”,”or”,”that”,”the”,”this”,”to”,”was”,”what”,”when”,”where”,”who”,”will”,”with”,”the”,”www”,”and”,”or”,”if”,”but” and any various others we find that aren’t commonly associated with the article subject. Then we can do a search on Digg and scrape several comments from the results, change up the usernames and make it all look unique. Hell if we wanted we could even markov some user submitted content in the middle of the scraped user content. Naturally not every user contributed content will match the topic exactly but who’s to say it’s not real? Once again as long as you remain “questionable” who can possibly deny you rankings? “Wow great article.”, “I pee’d in your pool.” <- users always submit this kind of shit, search engines are used to it and are more than well adapted to handle it. I realize this goes against the long preached world of “poison words” and such, but with the evolving net of social networking it directly conflicts with the true nature of the web and thus must be compensated for. Remember, its not what content you have, it’s how you use it. If it helps think about it like this. If you took all the comments on Youtube(which is the majority of their actual text based content) and truncated it all together in paragraph markers, how fast would you get banned? In no time, right. However when clones of places like Youtube organize it under headings of Comments and heavily break it up, somehow it all becomes legit. Take a moment to think about that.
More on this in a later post…
So now that we got our two elements of a successful gray hat site we can cook ‘em up together. We can even create a little mock voting and submission system. It doesn’t even have to work properly just as long as upon inspection it all looks legit. It’s all 100% autogenerated of course but as long as it’s laid out cleanly and correctly there’s no reason why we can’t generate hundreds of thousands of pages of stolen content while keeping visitors and the SE’s none the wiser. There’s no doubt we can do this exact technique for just about any authority site on the web. Let’s jump back to our Youtube example for a moment. Youtube isn’t the first nor the last video site on the web. As far as actual text based content goes it obviously takes a large piece of the brown cake. So how does it get away with it, and all it’s pages rank and do well while your clean and lengthy white hat articles struggle? Some would argue links are the answer. Well not all video content sites have tons of links but they can still survive and don’t get immediately banned for spammy content, but we’ll humor the notion anyway. So let’s get some links.
Gray hat sites frequently have an advantage over black hat sites in link building because since they can pass human check their links, more often than not, will tend to stick more. So of course the first place I would go is to attempt trackback pings on all these stories. If my link ends up on a few authoritative news sites, great, on a few blogs, just as well. Since it’s all legit and not only can we pass human check with our essentially black hat site as well as actually linking to them then there’s no good reason the links won’t have a high success rate. Which leads me to a bit of custom comment spam. Might as well find blog posts talking about related stuff to each story and leave something like, “I saw an interesting story related to this on www.blahblah.com/story123.” Sure why not, between just those two simple and common black hat techniques we somehow ended up with plenty of white hat links. Thats the beauty of gray hat. If you can at least get people to question whether or not your site is legit than you stand a very good chance of succeeding.
So essentially what we’re trying to do is play around within the margins between the pros of black hat and white hat till we can find a happy medium that is both acceptable to other webmasters and the search engine antispam algorithms, but how would an advanced Blue Hatter spin all this? Very good question. I personally would take a look at my potential competition. Since I’m taking these articles from other sources, they are the originals I am the linking to copy, naturally they will beat me out in all the SERPS. I can still drive traffic off their coattails perhaps by utilizing a few techniques to improve my CTR in the organics. However I’m still not ever going to reach my full traffic potential with the current gray hat setup. This is mostly due to my article titles being the exact same. I might have better luck if I can change up the titles and monetize on the surfers who search for slightly different variations to the topic. Let’s say for instance that one of the titles is, “Hilton’s Chiwawa Caught Snorting Coke In Background of Sex Video.” Alright so when I import my titles I can do a simple replacement algorithm to swap any instances of “Hilton” without the Paris for “Paris Hilton.” Or “Congressman Paul” for “Congressman Ron Paul.” If I wanted to capitalize on these possible search variations on a mass scale I could easily incorporate a thesaurus and swap out nouns for instance. Rock becomes Stone…etc. etc. IMDB also has a huge database of celebrity names I could possibly use for the example above. It’s all pretty endless and can get quite in depth, but I know if I do it right it’ll pay off big time. I may even get lucky and hit pay dirt with a big story coming out where everyone searches for something similar but not quite the same as the original headlines.
And that is how you be a gray hat
For shits and giggles I want to throw one more possible site structure available out there and get your opinions on it….How about Del.icio.us?
