Follow Up To 100’s Of Automated Links/Hour Post
Posted By Eli On May 6, 2007 @ 1:23 pm In Black Hole SEO | 162 Comments
This is a follow post to my [1] 100’s Of Links/Hour Automated - Black Hole SEO post.
I’m going to concede on this one. I admittedly missed a few explanations of some fundamentals that I think left a lot of people out of all the fun. After reading a few comments, emails and [2] YellowHouse for good measure) I realize that unless you already have adequate experience building RSS Scraper Sites than its very tough to fully understand my explanation of how to exploit them. So I’m going to do a complete re-explanation and keep it completely nontechnical. This post will become the post to explain how it works, and the other will be the one to explain how to do it. Fair enough? Good, lets get started with an explanation of exactly what a RSS scraper site is. So once again, this time with a MGD in my hand, cheers to Seis De Mayo!
Fundamentals Of Scraping RSS
Most blogs automatically publish an RSS feed in either a XML or ATOM format. [3] Daypop.
So when a black hatter in an attempt to create a massive site based on a set of keywords needs lots and lots of content one of the easiest ways would be to scrape these RSS Aggregators and use the Post Titles and Descriptions as actual pages of content. This however is a defacto form of copyright infringement since they are taking little bits of random people’s posts. The post Title’s don’t matter because they can’t be copyrighted but the actual written text can be if the person chose to have description within their feed include the entire post rather than just a snippet of it. I know it’s bullshit how Google is allowed to republish the information but no one else is, but like i said its defacto. It only matters to the beholder(which is usually a bunch of idiotic bloggers who don’t know better). So to keep in the up and up the Black Hatters always be sure to include proper credit to the original source of the post by linking to the original post as indicated in the RSS feed they grabbed. This backlink slows down the amount of complaints they have to deal with and makes their operation legitimate enough to continue stress free. At this point they are actually helping the original bloggers by not only driving traffic to their sites but giving them a free backlink, Google becomes the only real victim(boohoo). So when the many many people who use public RSS Scraper scripts such as Blog Solution and RSSGM on a mass scale start producing these sites they mass scrape thousands of posts from typically the three major RSS Aggregators listed above. They just insert their keywords in place of my “puppy” and automatically publish all the posts that result.
After that they need to get those individual pages indexed by the search engines. This is important because they want to start ranking for all these subkeywords that result from the post titles and within the post content. This results in huge traffic. Well not huge, but a small amount per RSS Scraper site they put up. This is usually done in mass scale over thousands of sites (also known as Splogs, spam blogs) which results in lots and lots of search engine traffic. They fill each page with ads (MFA, Made For Adsense Sites) and convert the click through rate on that traffic into money in their pockets. Some Black Hatters make this their entire profession. Some even create in the upwards of 5 figures worth of sites, each targeting different niches and keywords. One of the techniques they do to get these pages indexed quickly is to “ping” Blog Aggregators. Blog aggregators are nothing more than a rolling list of “recently updated blogs.” So they send a quick notification to these places by automatically filing out and submitting a form with the post title, and url to their new scraped page. A good example of the most common places they ping can be found in mass ping programs such as [4] Weblogs. They also will do things such as comment spam on blogs and other link bombing techniques to generate lots of deep inbound links to these sites so they can outrank all the other sites going for the niche the original posts included. This is a good explanation of why Weblogs.com is so worthless now. Black Hatters can supply these sites and generate thousands of RSS Scraped posts daily. Where legitimate bloggers can only do about one post every day or so. So these Blog Aggregator sites quickly get overrun and it can easily be assumed that about 90% of the posts that show up on there are actually pointed to and from RSS Scraper Sites. This is known as the Blog N’ Ping method.
I’m going to stop the explanation right there, because I keep saying “they” and it’s starting to bug me. Fuck guys I do this to! Haha. In fact most of the readers here do it as well. We already know tens of thousands, if not more, of these posts go up everyday and give links to whatever original source is specified in the RSS Aggregators. So all we got to do is figure out how to turn those links into OUR links. Now that you know what it is at least, lets learn how to exploit it to gain hundreds of automated links an hour.
What Do We Know So Far?
1) We know where these Splogs (RSS Scraper sites) get their content. They get them from RSS Aggregators such as [5] Google Blog Search.
2) We know they post up the Title, Description (snippet of the original post) and a link to the Source URL on each individual page they make.
3) We know the majority of these new posts will eventually show up on popular Blog Aggregators such as Weblogs.com. We know these Blog Aggregators will post up the Title of the post and a link to the place it’s located on the Splogs.
4) We also know that somewhere within these post titles and/or descriptions are the real keywords they are targeting for their Splog.
5) Also, we know that if we republish these fake posts using these titles to the same RSS Aggregators the Black Hatters use eventually (usually within the same day) these Splogs will grab and republish our post on their sites.
6) Lastly, we know that if we put in our URL as the link to the original post the Splogs, once updated, will give us a backlink and probably post up just about any text we want them to.
We now have the makings of some serious inbound link gathering. ![]()
How To Get These Links
1) First we’ll go to the Blog Aggregators and make a note of all the post titles they provide us. This is done through our own little [6] scraper.
2) We take all these post titles and store them in a database for use later.
3) Next we’ll need to create our own custom XML feed. So we’ll take 100 or so random post topics from our database and use a script to generate a .xml RSS or ATOM file. Inside that RSS file we’ll include each individual Title as our Post Title. We’ll put in our own custom description (could be a selling point for our site). Then we’ll put our actual site’s address as the Source URL. So that the RSS Scraper sites will link to us instead of someone else.
4) After that we’ll need to let the three popular RSS Aggregators listed above (Google,Yahoo,Daypop) know that our xml file exists. So, using a third script, we’ll go to their submission forms and automatically fill and submit each form with the URL to our RSS feed file(www.mydomain.com/rss1.xml). Here are the forms:
[7] Google Blog Search
[8] Yahoo News Search
[9] Daypop RSS Search
Once the form is submitted than you are done! Your fake posts will now be included in the RSS Aggregators search results. Then all future Splog updates that use the RSS Aggregators to find their content will automatically pickup your fake posts and publish them. They will give you a link and drive traffic to whatever URL you specify. Want it to go to direct affiliate offers? Sure! Want your money making site to get tens of thousands of inbound links? Sure! It’s all possible from there, its just how do you want to twist it to your advantage.
I hope this cleared up the subject. Now that you know what you’re doing you are welcome to read the original post and figure out how to actually accomplish it from the technical view.
162 Comments To "Follow Up To 100’s Of Automated Links/Hour Post"
#1 Comment By Glen On May 6, 2007 @ 2:07 pm
Great followup to another fantastic set of posts Eli.
Im sure people have learned a lot
Top Class
Glen
#2 Comment By Nis On May 6, 2007 @ 2:11 pm
I love it. I’m building a Rails app to do this automagically.
#3 Comment By Bill On May 6, 2007 @ 2:33 pm
Thanks Eli, didn’t get the description piece the first time.
#4 Comment By Raven Riley Fans On May 6, 2007 @ 3:38 pm
Great following posting ![]()
Just one detail question:
Should I use only 1 promotion text in my rss-feed for all the random titles or is this spammy and won’t get listed.
and if everyone works in their rss-feeds with only 1 text is would be easy for RSS Scraper to check if a Feed is real or a fake ![]()
Just an idea for your Scraper sites to solve the attacking problem for your own sites *hehe*
#5 Comment By John On May 6, 2007 @ 4:08 pm
After you told us to think about it, I figured out how to target the traffic… Its funny, cause I was thinking of really complex ways to do it, the answer was so simple.
#6 Comment By chatmasta On May 6, 2007 @ 4:28 pm
You could use a set of X descriptions and just randomly choose from them. But this is only if you even want to bother in the first place. What you are really going for is the link. ![]()
#7 Comment By Chad On May 6, 2007 @ 7:26 pm
This post is brilliant! Thanks for sharing.
I’ve written a C# scraper/feed generator/pinger tool and can gather keyword based feed data from blogsearch with ease.
My goal is to increase traffic to some of my sites. I want use the method you described in this post to do that. What I’m doing now, is each link in the generated feed points back to my homepage. That seems like a bad practice as every link is the same (and aren’t deep links either). Any advice on using this to more effectively increase traffic for my sites without being spotted? ![]()
Thanks!
#8 Comment By markj On May 6, 2007 @ 7:34 pm
Thanks Eli. That was a great break-down of the whole technique.
#9 Comment By Blain Reinkensmeyer On May 6, 2007 @ 8:13 pm
Thanks Eli, I needed the beginner breakdown for this process, scrapping is now something I actually understand ![]()
#10 Comment By bah humbug On May 6, 2007 @ 8:14 pm
Man, the 1st post about this made the scales fall from my eyes made me realize how i was putting he cart before the horse, made me understnd what they keep telling me at syndk8…and now you went and dumbed it down below my level grr too much competition
#11 Comment By Eli On May 6, 2007 @ 9:09 pm
lol, I hear ya there man. Just keep in mind. Weblogs.com alone posts over 2mb of new titles every 5 minutes. That’s anywhere from 10k titles to 100k titles. Also consider this, each title you post back up isn’t just going to get you one single link. It may very well get you none but more often than not it’ll actually score you several bites. Especially if the topic happens to hit a big term like “blog” or “information.” Sometimes if you do targeting and you get the pharmaceutical niche they’ll give hundreds of links per title you republish.
Likewise, understand that no matter how big people start talking in the comments, the reality is very few will actually follow through and successfully do this technique to a level that would be comparable to “competition.” To even hit a small fraction of a percentage of the possibility this technique holds it takes some serious server power. Most newbies, even though they now understand what needs be done, won’t have the resources or be capable of pulling it off on any sort of scale with their shared hosting accounts or VPS. So if it puts your mind at ease…I think your in the clear to do this idea ![]()
#12 Comment By Aengus @ Awestyproductions On May 6, 2007 @ 11:00 pm
This helped me understand the last post so much better.
Thanks ![]()
#13 Comment By Cucirca On May 7, 2007 @ 12:03 am
Thanks Eli.
You’re the best.
I’ll try to brake my shared hosting account this week.
Keep up the good work ![]()
#14 Comment By Glen On May 7, 2007 @ 2:33 am
Care to share? ![]()
#15 Comment By Beerhat On May 7, 2007 @ 5:23 am
I respect everything you have written on this most excellent Blog of yours. I admired you more, after I read you had a Guiness in your hand….but now you say you have an MGD? Come on dude, that’s a big fall from grace..LOL
Hey excellent post and cheers. I drink Guiness and Coors light so I guess I’m guilty of the good/bad beer syndrome as well.
#16 Comment By julien On May 7, 2007 @ 6:26 am
lightbulb just went off over my head. thanks.
#17 Comment By AC On May 7, 2007 @ 9:48 am
if you know the words you are trying to get scraped up by the BHs, what is the use with scraping up the titles, why not just ping up the keywords straight off your atom?
#18 Comment By lucab On May 7, 2007 @ 10:36 am
excellent post. i am coming out of my lurking state and will actually begin to leave comments.
btw, this is my favorite blog hands down!
#19 Comment By Eli On May 7, 2007 @ 10:57 am
“if you know the words you are trying to get scraped up by the BHs”
I think the entire point behind this, is that you don’t know.
you don’t know what keywords are trying to be scraped. All you know is that those keywords are somewhere within the titles. Also titles like “Puppy Food” gets picked up by scrapers for both the term puppy and food. So there is that benefit as well.
#20 Comment By KeywordDonkey On May 7, 2007 @ 11:00 am
Eli,
What are the drawbacks?
#21 Trackback By Search Engine Land: News About Search Engines & Search Marketing On May 7, 2007 @ 11:21 am
SearchCap: The Day In Search, May 7, 2007
Below is what happened in search today, as reported on Search Engine Land and from other places across the web:…
#22 Comment By Marketingmix On May 8, 2007 @ 3:51 am
Hm, interesting posts, but what I didn’t get is step 3, how to build from all these posts in my database individual posts and titles with sense, which refer to my own pages ?
Also how to define my own link destinations ?
Or do you use the same destinatiomn page for all links ?
#23 Comment By S On May 8, 2007 @ 5:42 am
I make today manually what you said and I am waiting for results. Can you tell me in how many days it will appear the results?
#24 Comment By AnonCow On May 8, 2007 @ 9:36 am
You better watch your mouth there Eli boy, them’ ther’ are split testing words.
#25 Comment By Eli On May 8, 2007 @ 10:05 am
ROTFL, I seriously just got soda in my nose after reading that. ![]()
thanks for the best nerd pun i’ve heard all week.
#26 Comment By Torrent Score On May 8, 2007 @ 3:20 pm
Hey Eli,
Nice post but one small detail for any less advanced people here, you don’t actually have to create a scraper script in order to pull this off, I sat around last night about the various ways to implement various techniques like this and have came upon a few good ones.
First you can utilize Wordpress and one single plugin that requires two lines to be tweaked, you can set it up to be 100% automated if you wanted to, the only downfall to using this technique is the start up will take a little longer then just using a scraper script but you can have a lot more control over your titles, categories, and things like that, you can also completely customize all your messages.
Pretty much the same as what you do with a regular scraper but done another way to give you a bit more control over the whole system. Both ways will work great though.
This comment was meant more for rambling purposes to show people that if you don’t know much about building your own scrapers just get creative and pull it off.
#27 Comment By Eidi On May 8, 2007 @ 6:18 pm
Just to let you know, Jason from [11] http://www.jasonberlinsky.com/ sells a script based on this post. He sells it for 450$ for the unlimited sites version. I bought it and I didn’t have any success with it. It’s my personal experience, but it’s totally buggy and it crashes after 30 seconds. The script is encrypted, so there’s no way to debug it.
I would suggest to keep your money or wait for a few updates from Jason before buying it or make your own if you have the skills ![]()
#28 Comment By Torrent Score On May 9, 2007 @ 12:58 am
I’ve seen a few people that have created similar scripts for around the same price, in my mind I think $450 bucks is an insane price to be paying, tomorrow I’m going to be creating a tutorial about how you can leverage Wordpress to achieve the same results as if you were to create or buy one of these $450 dollar scripts.
I’ve got a few people interested already and I might give the first few away for pretty much nothing but the price won’t be going over $60 or at the most $80 bucks for it, the tutorial will contain everything you’ll need to do what is described here but just in a different way.
The only real downfall to my method is you’ve got to spend an extra 10 to 20 minutes at the initial start up to get the ball rolling.
I don’t know maybe its just me but I’ve never had the heart to charge so much for something that can be done using a little extra creativity.
#29 Comment By Frank On May 9, 2007 @ 1:03 am
What is the plugin for wordpress that you are talking about?. Do you mean using feedwordpress and then editing it so it replaces all the urls with your site url?
#30 Comment By Lars Koudal On May 9, 2007 @ 1:54 am
I think he is referring to the FeedWordpress plugin. If that is the case, I dont think he got the point of this idea of Eli’s.
#31 Comment By Thomas On May 9, 2007 @ 2:24 am
this is what we don´t need. selling such script to people who don´t know what they do. but like always people think just in one way.
#32 Comment By tobsn On May 9, 2007 @ 6:10 am
lyceum ![]()
#33 Comment By Chris On May 9, 2007 @ 7:30 am
Any advice for those of us who dont have a dedicated server? Would it still be effective if we slowed the script down and was more selective over posts etc?
Also any warnings re using it on clean servers?
I.e. i have a clean site should i keep the script / new site off that server [new domain ofc]
#34 Comment By Ken On May 9, 2007 @ 8:46 am
Is there any advantage to making the description fields unique either within an entire feed or within your feed history?
What I mean is… if my feed is going to consist of 100 titles, could I just make up 100 descriptions and then each time I update the titles and a feed updates just recycle the same hundred descriptions?
Or.. better yet, is there any problem if the 100 descriptions within the same feed are almost identical with some keyword insertion here and there?
#35 Comment By Eli On May 9, 2007 @ 9:09 am
The descriptions are completely open ended. You are welcome to do whatever you would like with them. Nothing you can do will harm you so just feel free to take it as far as you want. Randomizing the descriptions sounds like a very creative idea.
#36 Comment By Torrent Score On May 9, 2007 @ 9:21 am
I’m not referring to the FeedWordpress plugin, yes my method does deal with an RSS feed plugin but you’ve got to mod it a little bit in order to get it to work dynamically just as if you were using a scraper bot to do it for you, as well I’m dealing with Cron Jobs for automation.
I’ve got the overall point to Eli’s goal, I’ve done it before, its not something completely new, their are several ways in order to pull it off, its just that Eli’s way is 100% automated, well you can make it automated and was created for large scale applications.
Another words you could sit back and hit up 10,000 posts inside of a few hours if you wanted too, you could regulate that inside of your scraper script as well but my method does the same thing on a little bit of a smaller scale where you can have much more control over it.
Which method is better?, well as a developer both methods holds their pro’s and con’s and both will work just fine but Eli’s method can be focused more towards the advanced person who can build their own scraper scripts as where my method is toned down to suit the ones who cannot build their own scripts.
I will never claim anything great about my way or hype it up to something its not, plus I say Eli should get the additional credit for a new method because really it was not until I read these few posts that I decided to develop a way for the less advanced people to join in on the fun.
#37 Comment By Con On May 9, 2007 @ 9:54 am
I would think what you do with the description is going to depend on what goal you’re trying to achieve with this.
If all you’re looking for is links, then it shouldn’t mean squat what’s in the desc. (except that you want the link in there too just in case). If you’re looking for “traffic” you should have something worthwhile. You’ll no doubt get more traffic from a decently worded description than from scraped/munged/markoved junk.
On that note, for traffic, I’d even forget the whole scraping of titles and create a boatload that are in a database. Pull the title and description and links. Create the feed, submit it and away you go. More work upfront but for traffic, a decent title is the FIRST thing that someone sees. Hmmm…I’m off to try and pull this all together now.
BTW, Nice post and blog Eli. Been lurking for awhile. Some really good stuff here.
Con
#38 Comment By Ken On May 9, 2007 @ 9:57 am
I was just thinking that if I put a really unique string of words in each description, or at least part of it, then it would be easy to see if my feed is getting scraped well and making it to the search engines by doing a quote search on google and yahoo around my unique phrase. Just a thought.
#39 Comment By Mike On May 9, 2007 @ 10:07 am
Hi Eli,
I have read you blog since it began and you seem to always have something cool to post about.
Since I’m not a coder (except for COBOL) I did this:
I saved the weblogs change file.
I stripped out the blog titles in Excel.
I got an RSS layout and put it into notepad.
I built an Excel sheet where the tags are in cells and then added the blog titles along with my URLs and descriptions.
I saved this as a into my RSS text file and uploaded it to an unused domain.
I validated that the rss feed was OK.
I submitted the rss feed to Google, Yahoo, Pingomatic.
I posted 3 different rss feeds (rss1.xml, etc.) on this site with different URLs coded.
Despite all the steps it’s really not that bad to do manually but now for the question…
How can you check to see if this is working? I did a few Google blog searches for the post titles and nothing showed up. My stats do show a little activity but is there some way to see if you are really getting any backlinks?
Thanks,
Mike
#40 Comment By Ken On May 9, 2007 @ 10:09 am
If you use a common text string in your descriptions, you can just search yahoo or google for your string of unique text in quotes to see if your feeds are getting picked up by scrapers. At least that is what I am trying to do.
#41 Comment By Mike On May 9, 2007 @ 11:28 am
Hey Ken,
I tired that but didn’t see anything yet. Maybe because it’s only been a day?
#42 Comment By Ken On May 9, 2007 @ 12:54 pm
yes, i think it hasn’t been long enough. I’m just in the process of using this, and maybe Eli can chime in but you aren’t going to see results in the search engines for your unique text until a blog has first picked up your feed and posted it, and then until the search engines have made it around to indexing the page that posted your feed. All in all, I would guess it would be a week or two before you started noticing results and that they would just accumulate over time.
#43 Comment By Eli On May 9, 2007 @ 1:06 pm
Exactly, for at least the first couple weeks you won’t see anything. If you do see anything it’ll be failed trackback attempts from the few scripts that automatically send them on every post. If you use a squeeshy word(old post) you should be able to see your posts show up in the RSS aggregators, but thats not entirely recommended to add a bullshit word on to every title. It’s best just to do it, continue doing it until you start seeing results then gauge whether or not you need to increase or decrese. Until then kind of play it by ear.
#44 Comment By clviu On May 9, 2007 @ 1:08 pm
How much time I should wait until I see the results. This is what I did. I grabbed the first 10 news from Google blogsearch created an xml, changed one url with my own and submited to Google blogsearch.google.com/ping , yahoo ping and daypop. I waited one day and I didn’t saw any results. How much time I should wait until I see the results?
#45 Comment By clviu On May 9, 2007 @ 1:12 pm
I now saw you last post Eli, thanks.
#46 Comment By Eli On May 9, 2007 @ 1:43 pm
I”m not sure but perhaps you misunderstood. You grab the titles from places like weblogs.com and such and then put them into google/yahoo/and daypop. if you just grab from google and yahoo and daypop and put them back in it really doesn’t do very much. Also only doing 10 is a very tough measure of results. The idea is you do thousands an hour and you get hundreds of backlinks an hour. doing only 10 to test it out is kind of a hit and miss. You may hit 30 something backlinks from that and assume if you do 10,000 you’ll get 30,000 backlinks or you may get no backlinks and assume it doesn’t work. Neither is a adquate measurement for the technique.
#47 Comment By Jason On May 9, 2007 @ 2:38 pm
I’m going to guess that this is Aequitas, right?
Jason
#48 Comment By Jason On May 9, 2007 @ 2:39 pm
A final update has been sent to Eli for testing and verification. I trust that you are ready to receive the update ![]()
Jason
#49 Comment By Jason On May 9, 2007 @ 2:42 pm
The price is the deterring factor…that price makes people who don’t know what they are doing less likely to shell out the money.
Jason
#50 Comment By Ken On May 9, 2007 @ 7:57 pm
Ok, ran into a small problem. I am doing this for a real site without a blog. I haven’t linked my feed page from the rest of the site. I can, but the feed is such garbage I really don’t want a human to see it.
Most ping sites and aggregators ask for your URL. I assume I enter my .rss page rather than my homepage… But some like ping-o-matic look like they really are wanting your homepage and mine has none of this garbage on it. Does that pose a problem?
Also, since I’m not using blog software that auto pings… where is a script or something that I can use to ping all of the big sites and enter my information each time and automate all of this pinging?
#51 Comment By Frank On May 9, 2007 @ 8:53 pm
Check out blogpinger [12] www.cflwaves.com/projects/ (windows desktop) or sourceforge.net/projects/blogpingr
#52 Comment By netyolk On May 9, 2007 @ 9:15 pm
Sounds good. We just need to write a custom script to parse RSS Aggregators for feed urls and pass this list of feed urls to wordpress RSS feed plugin to pull the title and content. The benefit here is that we do not have to write RSS parsing since the plugin can do that. But, we may have to hack the RSS plugin so it saves all those pull into wordpress database. This should be the first steps. But once you get everything into database, you basically do almost anything since you just need to write minor script to re-package the info and feed them back to the Aggregators.
#53 Comment By Jeremy On May 10, 2007 @ 1:10 am
How exactly does pinging work with this sort of project? If I wanted to ping say google after every xml refresh, in the ping parameters, would name be each random name im pulling from the database or just a general name for the site im trying to get backlinks for? Also the url and changeurl parameters, url would be the url im trying to get backlinks for and changeurl would be the location of my xml file?
How quick should I ping? If I refresh the xml say every minute with 100 new entries and delete the old 100 entries, is that enough time for the crawlers to grab all the changes after I ping?
New to the whole pinging thing, the actual script was much easier to write!
Thanks
#54 Trackback By Professional Middleman On May 10, 2007 @ 4:53 am
Boatloads of Backlinks
I’ve been playing around with the Black Hole SEO backlink generator for a few days now (see Blue Hat SEO for details) and it’s too early to be seeing significant results although traffic on my targeted project is creeping up
#55 Comment By bubbles On May 10, 2007 @ 5:54 am
If you want help on pinging check this out:
[13] http://www.wickedfire.com/design-development-programming/11594-ping-server-php.html
#56 Comment By Peter On May 10, 2007 @ 6:51 am
#57 Comment By Keywords On May 10, 2007 @ 7:38 am
sooner or later, wouldnt everyone be practically scraping the same content and go into a continuous loop?
#58 Comment By andreyk47 On May 10, 2007 @ 8:29 am
i guess i am missing something here…
y does it matter where u get your titles from as long as u publish them back to the 3 major rss aggregators like google blog search?
and another relevant question is how do i grab the titles from weblogs.com since it does not provide any search or category options? do i just grab any title from the “Download the latest
Weblog change lists”???
thanks in advance for your reply
Andrew
#59 Comment By Keywords On May 10, 2007 @ 8:39 am
bump ^^
#60 Comment By andreyk47 On May 10, 2007 @ 8:50 am
thank you so much man - that’s something i’ve been looking for all over the place
#61 Comment By AnonCow On May 10, 2007 @ 11:00 am
of course, its is the old “tragedy of the commons,” that is the terroitory you work in so you have to except it. If you want to make money for ever and ever into the futere, you better learn how to make money in the here and know which always change.
Now Eli, i don’t really see what is the difference (on a philo level) between this and you smack the bastards with a fake open proxy bit EXCEPT, you have the fact that you are slaming the BH in their “Black Holes” to get link backs.
Maybe you should rename this post to “LinkBack Mountain?”
So, Eli, where is that post about the tinyurl already so i can start having some fun with my new project?
Cheers
— 5thGear (as in 5th of Vodka),
aka AnonCow
#62 Comment By Globalwarming Awareness2007 On May 10, 2007 @ 12:00 pm
blue hat conference (not related ![]() - [15] http://www.infoworld.com/article/07/05/10/microsoft-invites-hackers-back_1.html?source=rss&url=http://www.infoworld.com/article/07/05/10/microsoft-invites-hackers-back_1.html
- [15] http://www.infoworld.com/article/07/05/10/microsoft-invites-hackers-back_1.html?source=rss&url=http://www.infoworld.com/article/07/05/10/microsoft-invites-hackers-back_1.html
#63 Comment By Eli On May 10, 2007 @ 1:08 pm
Yes kinda, I actually had to explain this to at least 12 people yesterday. Once you republish the rss feed with the new titles you ping the Blog Aggregators NOT the RSS Aggregators. In other words you want to do the exact opposite of what the black hatters are doing. If you ping the RSS Aggregators than that just puts the title back up for others, who are using the technique, to scrape and steal. You don’t want others getting your titles. Which is why a good alternative would be to NEVER use my actual examples in my posts. I say Weblogs.com obviously because not only is it a good example but I personally am NOT using Weblogs.com to get my titles. Would I really be that stupid and detrimental to my own business?
As far as saturation goes, lets say 10 people use this exact same technique. They all grab the exact same titles at the exact same time. They republish them with a backlink to their sites. The blackhat sites who search for those keywords and get matched with the same title again, they will grab ALL of the results. In other words they will republish all 10 articles on their site. They will all have the same title which deminishes the other 9 peoples traffic possibilities but each of the 10 still gets the same amount of inbound links granted to them. No one actually looses. Except in the fact that the scraper site will then ping all of the posts to the RSS Aggregators again, hence 10 posts with the exact same title will show up, thus more chances of a person using this technique grabbing that title. So in that sense it creates a loop, but in reality since this is being duplicated amongst all the titles available plus all the new ones, it evens out perfectly. So once again you end up with the exact same title saturation levels as before. Does that clear it up?
Alternative:
Lets say it does get saturated and becomes a big waste of crap. Then forget scraping the titles, thats a luxury. Just simply start sending titles with your keywords in them to the Blog Aggregators. Then you’ll only get relevant links. With that, there is plenty of niches and scraper sites for everyone to easily share ten times over.
#64 Comment By 5thGear On May 10, 2007 @ 1:37 pm
Eli, i can see why you are in BH instead of marketing, you are going on and on to this monkey about the logical reason’s why this method should work. You won’t convince. See (s)he has a complete scarcity mentality.
You know i have studied under a _WORLD_ leader in stats (top 5 in the world, name in just about any stats book) even then i have to realize, that in stats, you only can prove as much as you can assume, a Cor. of Gdl’s 2nd.
At the end of the day you, stats to convince, emotions do. So if you are going to get this keyboard monkey off his monkey croch you will have to hit in on an emotional not logical level.
which leads us to the real point, don’t bother with the scarcity monkeys. You and I know that there is more then enough $ to go alround, and no matter how slick we think we
are the Google is making a hella of a lot more then we ever could dream of off _other peoples_ content.
#65 Comment By Eli On May 10, 2007 @ 1:53 pm
Good point.
In that case: Anoncow, I fucked your mother and this idea does work. ![]()
#66 Comment By 5thGear On May 10, 2007 @ 2:46 pm
that make me feels a lot better, i thought she was screaming on and on about an Extension Level Ivent Extension Level Ivent
#67 Comment By eddie On May 10, 2007 @ 5:41 pm
eli,
sorry for being so dense but i’m confused when to use what.
definitions:
blog aggregator: ping-o-matic, weblogs
rss aggregators: Google Blog Search, Yahoo News Search, & Daypop
blog post:
step 1 = get titles from blog aggregators
step 4 = ping rss aggregators
your comment (2007-05-10 13:08:29 )
Once you republish the rss feed with the new titles you ping the Blog Aggregators NOT the RSS Aggregators.
[is this backwards?]
also i’m not sure just because we are doing things opposite of black hat splog, means we are white hat blogs ![]()
#68 Comment By RenoRaines On May 10, 2007 @ 8:23 pm
Great post and great blog, now please finish Complete Guide To Scraping Pt. 3 =)
#69 Comment By Rob On May 11, 2007 @ 12:17 am
Thanks for the great posts Eli, putting this information out for the public to use and answering all these questions is a really nice and generous thing to do.
If you have the patience for another question: About how many new posts can you make per hour on your XML feed before Yahoo News, Google Blog Search, and Daypop will accept stop accepting the posts? You mentioned you use multiple feeds to handle the volume; is it also necessary to use multiple sites, or will these blog search sites accept a high volume of new posts from one site?
:)
#70 Comment By Eli On May 11, 2007 @ 12:22 am
Oh snap! I wrote that past and everything. I should get to posting it ![]()
Thanks for the reminder.
#71 Comment By Eli On May 11, 2007 @ 12:25 am
lol, I think our educated 5thGear reader would argue that -1 is not the opposite of 1. but yeah totally. This is either more white hat than white hat or its more black hat than black hat. As far as the technique goes though, you got that perfectly right this time. If you got any questions about it, be sure to let me know.
btw I love textlinkbrokers. I have 4 accounts through them. I hope that isn’t a problem ![]()
#72 Comment By Eli On May 11, 2007 @ 12:30 am
Welcome and great question Rob. I honestly have no idea. I’ve always just gone with the better to be safe than sorry approach. So with every xx titles scraped I produce an xml feed with a randomized numeric filename and submit that. With that, at least it seems to be infinite. I saw no point in attempting to do it all within a single feed and finding out how long before i can ping again. Seemed like a waste of coding time. ![]()
#73 Comment By Eli On May 11, 2007 @ 1:21 am
Hey wanna see something funny?
[16] 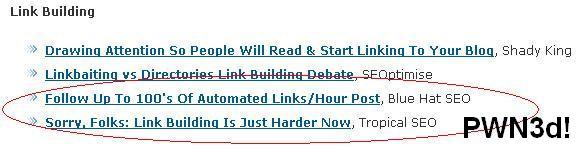
Ownage!
haha. I just thought that was ironically funny.
Just goes to show how much the Blue Hat readers kick ass compared to everywhere else on the net. Not to rip on Tropical SEO or anything but it’s like main stream SEO’ers are in the stone age compared to the readers here. Have we really moved that far ahead?
#74 Comment By andreyk47 On May 12, 2007 @ 4:55 pm
i still do not understand that. Why dont we just create fake xmls with whatever titles and content we want and submit them to all rss agregators?
as far as i understand black hatters are going to be using the keywords in the title to link back to your site. So u would want your own keywords to be in the title. isn’t that so? or i am totally of?
#75 Comment By camaromike On May 13, 2007 @ 5:04 pm
The reason you reuse the titles is because they blackhat sites usually target long tail keywords. For example, instead of “insurance”, the BHs will target something like “long term disbility insurance in New York”.
Re-using the titles is shooting fish in a barrel, using new titles is more like shooting in the dark.
#76 Comment By Arpit On May 13, 2007 @ 10:36 pm
So Eli, plz post it now.
#77 Comment By catz On May 14, 2007 @ 5:07 am
Torrent Score - I like the idea of using wordpress to handle all this - please let us know when you release your tutorial
#78 Comment By andreyk47 On May 14, 2007 @ 8:26 am
camaromike thanx,
I went over the explanation few more time - that helped as well ![]()
Than from what i understand what we are supposed to be doing is scraping all titles from weblogs and feedburner that contain our general keywords i.e. “pills”. The title might be short tail or long tail it does not matter as long as they contain our keyword (we don know what exactly BHs are scapping for). Than we create rss from those titles and ping them to 3 major RSS Aggregators where BHs would pick them up and post them on their splogs. Am i correct?
Than i have another question:
Do i have to have the scrapped content that i have put in the rss on my physical pages? i.e. i submit my rss to google blog search and in the rss i place a link back to the page on my site. Does that page have to contain the content from that rss?
Sorry guys for so many questions but i REALLY like this idea and i REALLY want to make sure i am getting it right. and i believe some other readers may have similar questions
Thanx for your help
#79 Comment By netyolk On May 14, 2007 @ 1:02 pm
i think the main purpose is to inject our link into the RSS feed. we scraping the title and used them in our feed to increase the chance that BHs will scrape our RSS since we know that the BHs are searching for some keywords among those title, we just don’t know which keyword. so, we scrape all titles. if the BHs scraped our RSS feed, which contains the title, content, and our injected url, the job is done. what we want is the trickle of traffic from the massive BH sites.
#80 Comment By Hijinks On May 16, 2007 @ 8:52 am
Ok…I got so far and now I am stuck and a little confused.
I scraped and got some titles, etc., created my rss feed with 100 titles and urls and then submitted them to Yahoo, Google and Daypop. If I want to do another 100 titles do I need to submit the updated feed to the 3 places again or will it just pick them up after I do the update.
I think I’m missing something here, I’ve read through this 3 times now lol…
#81 Comment By smitty On May 16, 2007 @ 11:41 pm
Hi. Long time reader first time caller
I get the whole concept, strategy, etc. But I dont have experiece with pinging Google Blog Search.
I saw they have an API and also a simple form that I could automate pinging to.
But, is there a stealth way of doing this? I mean, if I have one server, pinging to Google Blog Search about all the other blogs of mine, what’s your experience with Google Blog Search’s “cut off” filter?
And the other question is, how often have you tried this and NOT gotten indexed in the Google Blog Search?
#82 Comment By Mike On May 18, 2007 @ 6:13 am
Did anyone get this to work? Maybe this technique is no longer useful…
I’ve been running my splog for more than 3 days. All the spiders I can think of coming, but there is no traffic and the site does not appear in any indexes.
#83 Comment By Eli On May 18, 2007 @ 7:49 am
got the technique backwards ![]()
#84 Comment By Mike On May 18, 2007 @ 8:49 am
If it was backwards, then the money should have arrived first! ![]()
I am incorporating other titles in each post to make them appear a bit different from each other. But it seems that I can’t get any links. What could the problem be?
#85 Comment By Eli On May 18, 2007 @ 1:44 pm
We’re trying to get links FROM splogs and scraper sites. Not create them. ![]()
#86 Comment By Mike On May 18, 2007 @ 3:26 pm
Sorry, I meant that that I don’t get any links from other splogs to mine. I have no idea why they not linking me. What could be the problem?
#87 Comment By Teadja On May 22, 2007 @ 5:07 am
You missed to expalin us the most important part - how to get all that shit indexed by the engines ?
#88 Comment By Shawn On May 22, 2007 @ 7:46 pm
The majorly important part here is all the links from splogs. That’s what you care about.
#89 Comment By Smitty On May 23, 2007 @ 9:24 am
Hi Shawn, actually, I’d like to clarify his question, because your answer didn’t address it:
1) We understand that we’re creating blogs in the hopes that splogs will pick our content and link to us, when their automated blog-posting-softwares scan Google Blog Search for new content.
The question he has (and which I posted a few days ago) is: How do we get our blogs indexed and ranked in the Google Blog Search, so that we can complete the mission and have the splogs find our blogs in the first place?
I’ve done some searching, and haven’t found any specific tricks and descriptions on ‘how to get into Google Blog Search’ - My general at-face guess would be that it’s not necessarily easier than getting indexed/ranked in Google Proper.
Tricks, tips, strategies on this specific point would be appreciated. It is, in fact, the only unpredictable and “out of our hands” piece of this puzzle.
#90 Comment By Eli On May 23, 2007 @ 10:00 am
We’re creating blogs? None of the steps above say anything about creating a blog or any site for that matter. It says create an rss feed, thats all. This technique is strictly orientated around gaining links. It has nothing to do with even ranking in google blog search. Splogs and other rss scraper sites typically scrape ALL the results, many even go to the top 1,000 in the blog searches. Ranking really isn’t an issue.
Perhaps I’m misunderstanding the question.
#91 Comment By Seocracy On May 23, 2007 @ 10:56 am
Blogs? What are blogs?
If anyone is interested, I crafted a wee little utorial on how to implement this technique with backend databases using Ruby on Rails:
[17] www.undiggnified.com
I offer absolutely no guarantee that you are intelligent enough to make this work. ![]() have fun.
have fun.
#92 Comment By Tim On May 23, 2007 @ 3:52 pm
This technique came to mind when I saw all the blog postings listed at the new Google Trends page were just scraped postings of the Google Trends page. ![]()
#93 Comment By Smitty On May 23, 2007 @ 7:43 pm
Hey Eli, yes, I mis-stated. We are creating RSS Feeds that ‘imply’ that there are blogs. I know we’re not actually creating blogs, we’re creating rss feeds.
Let me state this simple:
I created a feed [18] http://www.domain.com/feed.xml
Submitted it to google blog search.
Neither the domain.com, nor the actual URLs in the feed.xml are listed anywhere in Google Blog Search. I submitted the feed over a week ago, and have re-submitted twice since (manually each time).
How quickly have you been seeing your feeds come up in Google Blog Search after you submitted?
Thanks
#94 Comment By Reaper On May 25, 2007 @ 5:57 am
Hi Eli
I sent you an email a while back but it looks like you never got it, so I’ll post my questions here:
I’ve got a working script but like others on here, I’m not seeing any results …
1. Is it worth notifying the popular ping servers blogs use when they have new posts in addition to manually adding the feeds to Google, Yahoo and DayPop?
2. In your experience, which quality of keyword should I target to scrape? Highly searched? Long tail? Somewhere in-between?
3. Are there any additional ways I can increase the chances my new feeds will show up in the KW search results at the various blog aggregators?
All tips gratefully received.
Ta!
#95 Comment By Foz On May 29, 2007 @ 4:25 am
So did this work for anyone?
Please report how you all got on
I wrote my own script. Been running more than a week and nothing good so far ![]()
#96 Comment By Reaper On May 29, 2007 @ 7:27 am
A quick update on my results so far:
After running the test campaign using a few keyword phrases for a week, I’ve had 6 clicks for a link to a PPL offer but no completions.
These aren’t exactly the results I was hoping for, but on the plus side the feeds are definitely getting indexed somewhere.
I’m wondering if I need to contact the ping services more often (currently every 5 hours, re-creating the RSS feed every hour) or choose different keywords, or something else.
Anyone want to give me any hints?
If you don’t want it public, feel free to email me here: reaper28 {AT} googlemail {DOT} com
All help welcomed! ![]()
#97 Comment By Alex On June 6, 2007 @ 2:13 pm
What’s the difference between using the link to the Yahoo form in the post and using the url [19] http://api.my.yahoo.com/rss/ping?u=http://www.mydomain.com/atom.xml
Also, what page do you submit to Daypop? It says it crawls the first page of the blog. Do you just go ahead and submit the page for the xml feed?
Thx
#98 Comment By Alex On June 6, 2007 @ 2:18 pm
Okay sorry about that but for some reason it wouldn’t accept my posts.
Anyway, I’m finishing up my script and would like to ask some questions about pinging.
I assume pinging and re-submitting the form with our feed is the same thing ![]()
a) What’s the difference between using the Yahoo form mentioned in the post and the url [20] http://api.my.yahoo.com/rss/ping?u=http://www.mydomain.com/atom.xml
b) Has Daypop changed since the post? They say the crawl the first page of the blog and that it might take a week for something to appear in their index. Do you just go ahead and submit the url to the xml feed anyway?
c) I was actually thinking of trying this from my home computer at first, rather than a dedicated server…. do the URLs of the feeds need to be permanent and stay the same for when the crawlers come to visit? Or is it usually 1 crawl per ping?
Thx in advance!
#99 Comment By Alex On June 6, 2007 @ 2:22 pm
Okay sorry about that, but Eli must have installed an anti-lame-ass-question filter or something. Whenever I try to post a couple of questions I have since I’m finishing up my script, comments don’t work.
When I post something silly like this message, I bet it’s gonna work!
:D
#100 Comment By Alex On June 9, 2007 @ 12:26 pm
Finished my script but my feed doesn’t seem to be indexed by google. Even if I submit it manually nothing shows up in the search results. Looks like a valid feed, I can even read it with a feed reader.
Any1 had the same problem?
#101 Comment By Robert On June 11, 2007 @ 1:19 am
Amazing how quickly people get excited and when the results are not instant, they lose momentum.
Didn’t Eli state to do it with consistency?
Now, where is my remote and “hurry up microwave.”
:-)
#102 Comment By fcreature On July 6, 2007 @ 6:16 pm
I know I’ve got a late start on this but after spending the most of today on the project I now have a script crawling several websites for blog titles. I’m up to about 30,000 titles just from the last few hours. I also have coded the rss feed generator, and the keyword organizer so that I can target specific products for the keywords. What do you think is a good amount of titles to be working with that will make this worth while?
Also, am I correct when saying that we are relying on the spammers to link back to our “fake blogs” for this to all work? Is that really a safe bet? Do the spammers actually include our links?
#103 Comment By stevo On July 22, 2007 @ 7:38 pm
Well, its 2 months on now. I’m sure most of you who did it are now listed in feeds. Any comments on how well it worked or didn’t? I’m curious.
#104 Comment By heartsbane On August 30, 2007 @ 1:24 pm
OK, I read these posts (and all comments) and then implemented my own version of this about a week ago. I decided to try it on a brand new domain/site, and that way I could easily tell that incoming links/traffic were coming from this technique. Thus far I haven’t had a single *human* visitor and can’t find any trace of a single incoming link to my site. So, here’s a little about my approach/experience followed by some questions. I’d love any insight/feedback anyone is willing to share!
- To keep it simple (for now) I decided to implement this using a simple XSL transform. Basically, I wrote a script that downloads the latest [21] http://rpc.weblogs.com/shortChanges.xml XML and translates it into a new RSS feed that keeps the title but replaces the link/description with my homepage url and a site description that includes some embedded links on keywords. Since I also wanted to narrow it down to around 100 or so entries in my RSS feed, I’m only keeping title that are > 40 characters and
#105 Comment By Stumble Exchange On September 6, 2007 @ 10:59 am
As fare as i can tell that shortchanges is a non-optimal tool to scrape from because it contains the titles of the blogs, and the scrapers are searching for the titles of the posts. Scrape the blog searche result titles instead. The sites that get these links are slogs and it takes a while to show up.
#106 Comment By Stumble Exchange On September 6, 2007 @ 11:01 am
argv i lost my post.
So ya the shortsChanges.xml shows the title of the blogs not the titles of the posts. The splogs search the titles of the posts. So scrape the titles from blog search engines instead.
These are splogs that are scraping and they aren’t exactly top piority for the search engines to get into the indexes, so expect links to take a while to show up.
#107 Comment By Garchoun Masam On October 6, 2007 @ 2:27 pm
thank u for this useful post ![]()
#108 Comment By Madhuri Dixit On December 10, 2007 @ 1:02 pm
Thanks Eli. That was a great break-down of the whole technique.
#109 Comment By Brian On February 17, 2008 @ 12:47 pm
very good post thanks for sharing. I will give it a try and see how it goes.
#110 Comment By zamdoo On February 28, 2008 @ 4:32 am
Great concept. Looks a bit technical, but still gonna work through on it as it looks like a winner. Thanks.
#111 Comment By Stephen On September 21, 2008 @ 2:00 pm
So the question is:
Results?
This looks good in theory and I am ready to do the coding but I would like to hear at least 1 person say that it is working before I spend the time on the project to find that it doesn’t work for whatever reason.
Does anyone have a domain that is using this logic where they can show a
link:www.domainthatisusingthis.com
with inbound links that are from the splogs?
Eli, this question is pointed at you specifically. I like your concepts and they seem valid so show me the results please.
#112 Comment By Tom On February 17, 2009 @ 1:40 am
Very old post,want to know if it works now.Because it will waste me many time to do test
#113 Comment By Gry dla Dzieci On April 3, 2009 @ 6:23 am
Please add 0 to 0 - stupid captcha
#114 Comment By Pozycjonowanie Poznan On April 15, 2009 @ 12:48 am
Amazing post. Thanks.
#115 Comment By Nate On August 16, 2009 @ 10:20 pm
Old post, but worth the shot. I hope this technique still exists!
#116 Comment By Golden triangle tour On October 7, 2009 @ 12:06 am
Well done, nice content, nice information and excellent writting style……keep it up……thanks
#117 Comment By Payday Uk On October 10, 2009 @ 3:02 am
Thanks for providing me the real information about RSS feed.
#118 Comment By Newsflx On November 12, 2009 @ 10:36 am
i think google blog search spiders the links in rss feeds and displays the title and description as given by the domains meta tags.
so a fake feed with fake titles and descriptions will be useless.
#119 Comment By The Lord On December 6, 2009 @ 7:29 am
I tried this yesterday without success. I wasn’t able to get any of my fake posts into the index. Maybe this technique ist too old.
#120 Comment By rude jokes On April 10, 2010 @ 12:57 pm
Torrent Score - I like the idea of using wordpress to handle all this - please let us know when you release your tutorial
#121 Comment By Living On Dividends On April 29, 2010 @ 10:45 pm
Is this working for anyone? Does anybody have any updates?
I wonder if this is one of those techniques that USED to work but doesn’t anymore.
#122 Comment By Forum Roleplay On September 22, 2010 @ 5:11 pm
Consistency and dedication are the key to all things! No one should expect instant results from anything except a Google search, or a search for any other engine but I think I’ve made my point.
#123 Comment By Скачать фильм On October 1, 2010 @ 4:54 am
this is what we don´t need. selling such script to people who don´t know what they do. but like always people think just in one way.
#124 Comment By India Tour Packeges On October 9, 2010 @ 11:13 am
There’s always some new ideas to read up on here. If you’re able to program in perl and PHP this place is a gold mine.
#125 Comment By unemployed loans On October 13, 2010 @ 7:14 am
Here is a great work that is too good for bookmarking.
#126 Comment By SEO Miami On November 28, 2010 @ 12:21 pm
Some of this is beyond the comprehension of my small brain. lol. nice post.
#127 Comment By شات كتابي On December 30, 2010 @ 7:17 am
Thanks for great tutorial
#128 Comment By porno On May 12, 2011 @ 8:59 am
e let us know when you release your tutorial
#129 Comment By karen millen uk On June 2, 2011 @ 12:01 am
I just added this weblog to my feed reader, great stuff. Can’t get enough!
#130 Comment By Rajib Kumar On June 8, 2011 @ 11:20 am
Automated links is a nice post … thanks for share
#131 Comment By ผ้าม่าน On June 20, 2011 @ 1:42 am
lklk
#132 Comment By David On July 10, 2011 @ 12:42 am
i just submited my own rss feed .
great read , thanks.
#133 Comment By Work Online On August 8, 2011 @ 2:48 am
Awesome tutorial indeed.This is an interesting article to encourage more visitors.
#134 Comment By Work Online On August 8, 2011 @ 2:49 am
I’m glad that you shared this helpful info with us. Please keep us informed like this. Thanks for sharing.
#135 Comment By Caldaie Ferroli On September 24, 2011 @ 7:15 am
I’ve been meaning to start a video blog for some time now
#136 Comment By مدونة On September 26, 2011 @ 8:27 am
keep it up
thanx
#137 Comment By internet marketing On September 28, 2011 @ 12:57 pm
Many things have changed Panda, what worked 3 years ago probably won’t work today. Google’s made it pretty tough for every [22] internet marketing out there. It’s about getting your hands dirty now, but not with blood (black hat) but with real work.
#138 Comment By Kuhinje On October 14, 2011 @ 8:13 am
Amazing post. Thanks.
#139 Comment By Property Marbella On October 16, 2011 @ 7:59 pm
Cool, I make today manually what you said and I am waiting for results.
#140 Comment By Ritesh On November 19, 2011 @ 2:32 pm
nice
[23] Do follow list PR 7 Blogs SEO
#141 Comment By شات مصرى On December 19, 2011 @ 2:53 am
lol nice website chat p7bk chat egypt good
#142 Comment By Website translation On December 20, 2011 @ 4:43 pm
Sounds like stealing from thieves… I love it!
#143 Comment By شات صوتي On January 4, 2012 @ 8:04 am
OKKKKKKKKKKKKKKKKKKKKK
#144 Comment By سعودي انحراف On January 4, 2012 @ 8:04 am
YEEEEESSSSSSSSSSS
#145 Comment By Nitish On January 6, 2012 @ 5:24 am
Great Post, and the title itself is so appealing lol
#146 Comment By Nitish On January 6, 2012 @ 5:25 am
Lol what you saying okkkkkkkkk for?
#147 Comment By Nitish On January 6, 2012 @ 5:25 am
I would second that
#148 Comment By Nitish On January 6, 2012 @ 5:26 am
Getting 100’s of automate link in an hour is way more than what most people make in a day or two
#149 Comment By Ismat Zahra On January 8, 2012 @ 4:15 am
nice….
#150 Comment By Ismat Zahra On January 8, 2012 @ 4:16 am
Gr8 post ![]()
#151 Comment By Ismat Zahra On January 8, 2012 @ 4:17 am
helpfull for every one ![]()
#152 Comment By Ismat Zahra On January 8, 2012 @ 4:18 am
:)
#153 Comment By Property Marbella On February 8, 2012 @ 1:31 am
Thanks Eli, didn’t get the description piece the first time.
#154 Comment By Classificados On March 6, 2012 @ 2:44 pm
Thanks for this article, very interesting.
#155 Comment By Crafts Factory On March 11, 2012 @ 3:20 am
Consistency and dedication are the key to all things! No one should expect instant results from anything except a Google search, or a search for any other engine but I think I’ve made my point.
#156 Comment By HealthWrong On March 20, 2012 @ 9:55 pm
thanks for the followup. very responsible of you ![]()
#157 Comment By Life Insurance Over 85 Years Old On April 5, 2012 @ 5:47 pm
not a good way to build links. anyway thanks for sharing.
#158 Comment By Justbeenpaid On April 29, 2012 @ 8:37 am
Google don’t like automated backlinks
#159 Comment By Mercy Ministries On July 16, 2012 @ 1:47 pm
I think this is an effective one. I will use this automated thing. It would really helpful for me to build links.
#160 Comment By hut be phot On September 2, 2012 @ 4:14 am
I’ve been playing around with the Black Hole SEO backlink generator for a few days now (see Blue Hat SEO for details) and it’s too early to be seeing significant results although traffic on my targeted project is creeping up
#161 Comment By thong cong On September 2, 2012 @ 9:46 pm
I’m glad that you shared this helpful info with us. Please keep us informed like this. Thanks for sharing.
#162 Comment By thong cong On September 8, 2012 @ 6:48 am
I love it. I’m building a Rails app to do this automagically.
Article printed from Blue Hat SEO-Advanced SEO Tactics: https://www.bluehatseo.com
URL to article: https://www.bluehatseo.com/follow-up-to-100s-of-automated-linkshour-post/
URLs in this post:
[1] 100’s Of Links/Hour Automated: https://www.bluehatseo.com/100s-of-linkshour-automated-introduction-to-black-hole-seo/
[2] YellowHouse: http://www.yellowhousehosting.com/resources/
[3] Daypop: http://www.daypop.com/search?q=puppy&s=1&c=10&ext=true&t=w&o=rss
[4] Weblogs: http://www.weblogs.com
[5] Google Blog Search: http://blogsearch.google.com/
[6] scraper: https://www.bluehatseo.com/complete-guide-to-scraping-pt-1/
[7] Google Blog Search: http://blogsearch.google.com/ping
[8] Yahoo News Search: http://search.yahoo.com/mrss/submit
[9] Daypop RSS Search: http://www.daypop.com/info/submit.htm
[10] 100’s Of Automated Links/Hour : https://www.bluehatseo.com/100s-of-linkshour-automated-introduction-to-black-hole-seo/
[11] http://www.jasonberlinsky.com/: http://www.jasonberlinsky.com/
[12] www.cflwaves.com/projects/: http://www.cflwaves.com/projects/
[13] http://www.wickedfire.com/design-development-programming/11594-ping-server-php.html: http://www.wickedfire.com/design-development-programming/11594-ping-server-php.html
[14] http://www.wickedfire.com/traffic-supreme/11706-instant-backlinks-ruby.html: http://www.wickedfire.com/traffic-supreme/11706-instant-backlinks-ruby.html
[15] http://www.infoworld.com/article/07/05/10/microsoft-invites-hackers-back_1.html?source=rss&url=http://www.infoworld.com/article/07/05/10/microsoft-invites-hackers-back_1.html: http://www.infoworld.com/article/07/05/10/microsoft-invites-hackers-back_1.html?source=rss&url=h
ttp://www.infoworld.com/article/07/05/10/microsoft-invites-hackers-back_1.html
[16] Image: http://searchengineland.com/070507-150740.php
[17] www.undiggnified.com: http://www.undiggnified.com
[18] http://www.domain.com/feed.xml: http://www.domain.com/feed.xml
[19] http://api.my.yahoo.com/rss/ping?u=http://www.mydomain.com/atom.xml: http://api.my.yahoo.com/rss/ping?u=http://www.mydomain.com/atom.xml
[20] http://api.my.yahoo.com/rss/ping?u=http://www.mydomain.com/atom.xml: http://api.my.yahoo.com/rss/ping?u=http://www.mydomain.com/atom.xml
[21] http://rpc.weblogs.com/shortChanges.xml: http://rpc.weblogs.com/shortChanges.xml
[22] internet marketing: http://www.optimum7.com/
[23] Do follow list PR 7 Blogs SEO: http://www.techinspiro.blogspot.com
Click here to print.