Advanced White Hat SEO Exists Damn It! - Dynamic SEO
Hello again!
I’ve been restless and wanting to write this post for a very long time and I’m not going to be happy until its out. So get out your reading glasses, and I have it on good authority that every reader of this blog happens to be the kind of dirty old men that hang out and harass high school chicks at gas stations so don’t tell me you don’t have a pair. Get ‘em out and let’s begin….
Fuck, how do I intro-rant this post without getting all industry political? Basically, this post is an answer to a question asked a long time ago at some IM conference to a bunch of gurus. They asked them does advanced White Hat SEO exist? If I remember right, and this was a long time ago and probably buzzed up so forgive me, every guru said something along the lines of there is no such thing as advanced White Hat SEO. Now I’m sympathetic to the whole self promotion thing to a small degree. If your job is to build buzz around yourself you have to say things that are buzz worthy. You can’t say the obvious answer, YOU BET IT DOES AND YOU’RE RETARDED FOR ASKING! You gotta say something controversial that gets people thinking, but not something so controversial that anyone of your popularity level is going to contradict in a sensible way making your popularity appear more overrated than a cotton candy vendor at the Special Olympics. In short, yes advanced white hat exists and there’s tons of examples of it; but you already knew that and I’m going to give you such an example now. That example is called Dynamic SEO. I’ve briefly mentioned it in several posts in the past and it is by every definition simple good ol’ fashion on-site keyword/page/traffic optimizing White Hat SEO. It also happens to be very simple to execute but not so simple to understand. So I’ll start with the basics and we’ll work into building something truly badhatass.
What Is Dynamic SEO?
Dynamic SEO is simply the automated no-guessing self changing way of SEOing your site over time. It is the way to get your site as close to 100% perfectly optimized as needed without ever knowing the final result AND automatically changing those results as they’re required. It’s easier done than said.
What Problems Does Dynamic SEO Address?
If you’re good enough at it you can address EVERY SEO related problem with it. I am well aware that I defined it above as on-site SEO, but the reality is you can use it for every scenario; even off-site SEO. Hell SQUIRT is technically dynamic off-site SEO. Log Link Matching is even an example of advanced off-site Dynamic SEO. The problems we’re facing with this post specifically includes keyword optimization which is inclusive of keyword order, keyword selection, and even keyword pluralization.
See the problem is you. When it comes to subpages of your site you can’t possibly pick the exact best keywords for all of them and perfectly optimize the page for them. First of all keyword research tools often get the keyword order mixed up. For instance they may say “Myspace Template” is the high traffic keyword. When really it could be “Templates For Myspace”. They just excluded the common word “for” and got the order wrong because “Template Myspace” isn’t popular enough. They also removed the plural to “broad” the count. By that logic Myspace Templates may be the real keyword. Naturally if you have the intuition this is a problem you can work around manually. The problem is not only will you never be perfect on every single page but your intuition as a more advanced Internet user is often way off, especially when it comes to searching for things. Common users tend to search for what they want in a broad sense. Hell the keyword Internet gets MILLIONS of searches. Who the fuck searches for a single common word such as Internet? Your audience is who. Whereas you tend to think more linear with your queries because you have a higher understanding of how Ask Jeeves isn’t really a butler that answers questions. You just list all the keywords you think the desired results will have. For instance, “laptop battery hp7100″ instead of “batteries for a hp7100 laptop.” Dynamic SEO is a plug n play way of solving that problem automatically. Here’s how you do it.
Create A Dynamic SEO Module
The next site you hand code is a great opportunity to get this built and in play. You’ll want to create a single module file such as dynkeywords.pl or dynkeywords.php that you can use across all your sites and easily plug into all your future pages. If you have a dedicated server you can even setup the module file to be included (or required) on a common path that all the sites on your server can access. With it you’ll want to give the script its own sql database. That single database can hold the data for every page of all your sites. You can always continue to revise the module and add more cool features but while starting out it’s best to start simple. Create a table that has a field structure similar to ID,URL,KEYWORD,COUNT. I put ID just because I like to always have some sort of primary key to auto increment. I’m a fan of large numbers what can I say? ![]()
Page Structure & Variables To Pass To Your Module
Before we get deep into the nitty gritty functions of the module we’ll first explore what basic data it requires and how the site pages will pass and return that data. In most coded pages, at least on my sites, I usually have the title tag in some sort of variable. This is typically passed to the template for obvious reasons. The important thing is it’s there so we’ll start with that. Let’s say you have a site on home theater equipment and the subpage you’re working on is on LCD televisions. Your title tag may be something like “MyTVDomain.com: LCD Televisions - LCD TVs”.
Side Note/
BTW sorry I realize that may bother some people how in certain cases I’ll put the period outside of the quotes. I realize it’s wrong and the punctuation must always go inside the quotes when ending a sentence. I do it that way so I don’t imply that I put punctuation inside my keywords or title tags etc etc.
/Side Note
You know your keywords will be similar to LCD Televisions, but you don’t know whether LCD TVs would be a better keyword. ie. It could either be a higher traffic keyword or even a more feasible keyword for that subpage to rank for. You also don’t know if the plurals would be better or worse for that particular subpage so you’ll have to keep that in your mind while you pass the module the new title variable. So before you declare your title tag create a quick scalar for it (hashref array). In this scalar you’ll want to put in the estimated best keywords for the page:
[
Keyword1 -> ‘LCD Television’,
Keyword2 -> ‘LCD TV’,
]
Then put in the plurals of all your keywords. It’s important not to try to over automate this because A) you don’t want your script to just tag the end of every word with “s” because of grammatical reasons (skies, pieces, moose, geese) and B) you don’t want your module slowing down all the pages of your site by consulting a dictionary DB on every load.
[
Keyword1 -> ‘LCD Television’,
Keyword2 -> ‘LCD TV’,
Keyword3 -> ‘LCD Televisions’,
Keyword4 -> ‘LCD TVs’,
]
Now for you “what about this awesome way better than your solution” mutha fuckas that exist in the comment section of every blog, this is where you get your option. You didn’t have to use a scalar array above you could of just have used a regular array and passed the rest of the data in their own variables, or you could of put them at the beginning of the standard array and assigned the trailing slots to the keywords OR you could use a multidimensional array. I really don’t give a shit how you manage the technical details. You just need to pass some more variables to the modules starting function and I happen to prefer tagging them onto the scalar I already have.
[
Keyword1 -> ‘LCD Television’,
Keyword2 -> ‘LCD TV’,
Keyword3 -> ‘LCD Televisions’,
Keyword4 -> ‘LCD TVs’,
URL -> ‘$url’,
REFERRER -> ‘$referrer’,
Separator -> ‘-’
]
In this case the $url will be a string that holds the current url that the user is on. This may vary depending on the structure of the site. For most pages you can just pull the environmental variable of the document url or if your site has a more dynamic structure you can grab it plus the query_string. It doesn’t matter if you’re still reading this long fuckin’ post you probably are at the point in your coding abilities where you can easily figure this out. Same deal with the referrer. Both of these variables are very important and inside the module you should make a check for empty data. You need to know what page the pageview is being made on and you’ll need to know if they came from a search engine and if so what keywords did they search for. The Separator is simply just the character you want to separate the keywords out by once its outputted. In this example I put a hyphen so it’ll be “Keyword 1 - Keyword 2 - Keyword 3″ Once you got this all you have to do is include the module in your code before the template output, have the module return the $title variable and have your template output that variable in the title tag. Easy peasey beautiful single line of code. ![]()
Basic Module Functions
Inside the module you can do a wide assortment of things with the data and the SQL and we’ll get to a few ideas in a bit. For now just grab the data and check the referrer for a search engine using regex. I’ll give you a start on this but trust it less the older this post gets:
Google: ^http:\/\/www\.google\.[^/]+\/search\?.*q=.*$
[?&]q= *([^& ][^&]*[^& +])[ +]*(&.*)?$
Yahoo: ^http:\/\/(\w*\.)*search\.yahoo\.[^/]+\/.*$
[?&]p= *([^& ][^&]*[^& +])[ +]*(&.*)?$
MSN: ^http:\/\/search\.(msn\.[^/]+|live\.com)\/.*$
[?&]q= *([^& ][^&]*[^& +])[ +]*(&.*)?$
Once you’ve isolated the search engines and the keywords used to find the subpage you can check to see if it exists in the database. If it doesn’t exist insert a new row with the page, the keyword, and a count of 1. Then select where the page is equal to the $url from the database order by the highest count. If the count is less than a predefined delimiter (ie 1 SE referrer) than output the $title tag with the keywords in order (may want to put a limit on it). For instance if they all have a count of 1 than output from the first result to the last with the Separator imbetween. Once you get your first visitor from a SE it’ll rearrange itself automatically. For instance if LCD TV has a count of 3 and LCD Televisions has a count of 2 and the rest have a count of 1 you can put a limit of 3 on your results and you’ll output a title tag with something like “LCD TV - LCD Televisions - LCD Television” LCD Television being simply the next result not necessarily the best result. If you prefer to put your domain name in your title tag like “MYTVSITE.COM: LCD TV - LCD Televisions - LCD Television” you can always create an entry in your scalar for that and have your module just check for it and if its there put it at the beginning or end or whatever you prefer (another neat customization!).
Becoming MR. Fancy Pants
Once you have the basics of the script down you can custom automate and SEO every aspect of your site. You can do the same technique you did with your title tag with your heading tags. As an example you can even create priority headings *wink*. You can go as far as do dynamic keyword insertion by putting in placeholders into your text such as %keyword% or even a long nonsense string that’ll never get used in the actual text such as 557365204c534920772f205468697320546563686e6971756520546f20446f6d696e617465. With that you can create perfect keyword density. If you haven’t read my super old post on manipulating page freshness factors you definitely should because this module can automate perfect timings on content updates for each page. Once you have it built you can get as advanced and dialed in as you’d like.
How This Works For Your Benefit
Here’s the science behind the technique. It’s all about creating better odds for each of your subpages hitting those perfect keywords with the optimal traffic that page with its current link building can accomplish. In all honesty, manually done, your odds are slim to none and I’ll explain why. A great example of these odds in play are the ranges in competitiveness and volume by niche. For instance you build a site around a homes for sale database you do a bit of keyword research and figure out that “Homes For Sale In California” is an awesome keyword with tons of traffic and low competition. So you optimize all your pages for “Homes For Sale In $state” without knowing it you may have just missed out on a big opportunity because while “Homes For Sale In California” may be a great keyword for that subpage “New York Homes” may be a better one for another subpage or maybe “Homes For Sale In Texas” is too competitive and “Homes In Texas” may have less search volume but your subpage is capable of ranking for it and not the former. You just missed out on all that easy traffic like a chump. Don’t feel bad more than likely your competitors did as well. ![]()
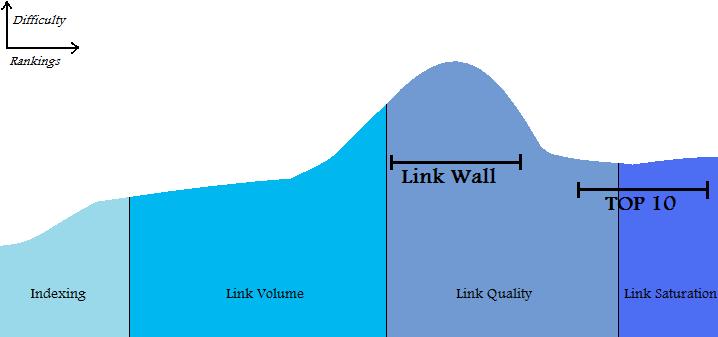
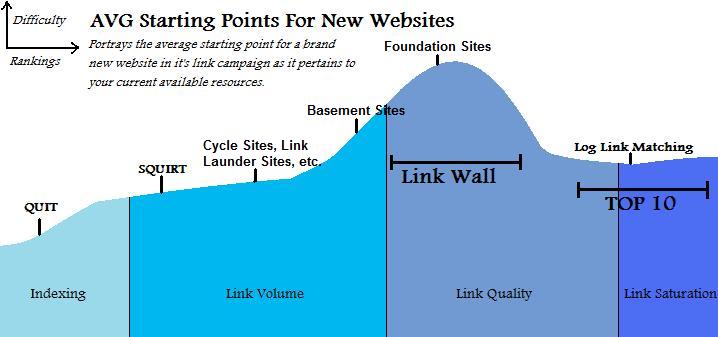
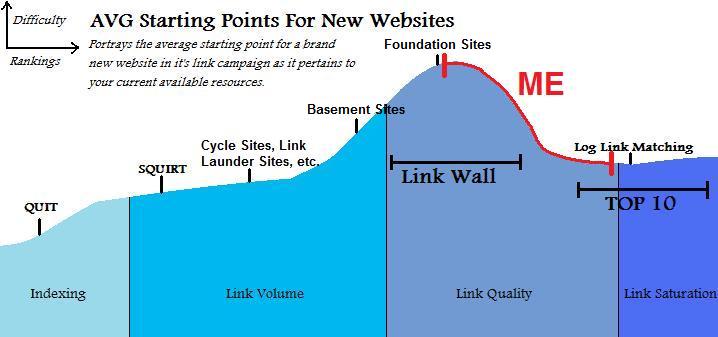
Another large advantage this brings is in the assumption that short tail terms tend to have more search volume than long tail terms. So you have a page with the keywords “Used Car Lots” and “Used Car”. As your site gets some age and you get more links to it that page will more likely rank for Used Car Lots sooner than Used Car. Along that same token once it’s ranked for Used Car Lots for awhile and you get more and more links and authority since Used Car is part of Used Car Lots you’ll become more likely to start ranking for Used Car and here’s the important part. Initially since you have your first ranking keyword it will get a lot of counts for that keyword. However once you start ranking for the even higher volume keyword even if it is a lower rank (eg you rank #2 for Used Car Lot and only #9 for Used Car) than the count will start evening out. Once the better keyword outcounts the not as good than your site will automatically change to be more optimized for the higher traffic one while still being optimized for the lesser. So while you may drop to #5 or so for Used Car Lot your page will be better optimized to push up to say #7 for Used Car. Which will result in that subpage getting the absolute most traffic it can possibly get at any single time frame in the site’s lifespan. This is a hell of a lot better than making a future guestimate on how much authority that subpage will have a year down the road and its ability to achieve rankings WHILE your building the fucking thing; because even if you’re right and call it perfectly and that page does indeed start to rank for Used Car in the meantime you missed out on all the potential traffic Used Car Lot could have gotten you. Also keep in mind by rankings I don’t necessarily always mean the top 10. Sometimes rankings that result in traffic can even go as low as the 3rd page, and hell if that page 3 ranking gives you more traffic than the #1 slot for another keyword fuck that other keyword! Go for the gold at all times.
What About Prerankings?
See this is what the delimiter is for! If your page hasn’t achieved any rankings yet than it isn’t getting any new entry traffic you care about. So the page should be optimized for ALL or at least 3-6 of your keywords (whatever limit you set). This gives the subpage at least a chance at ranking for any one of the keywords while at the same time giving it the MOST keywords pushing its relevancy up. What I mean by that is, your LCD page hasn’t achieved rankings yet therefore it isn’t pushing its content towards either TV or Televisions. Since it has both essentially equaled out on the page than the page is more relevant to both keywords instead of only a single dominate one. So when it links to your Plasma Television subpage it still has the specific keyword Television instead of just TV thus upping the relevancy of your internal linking. Which brings up the final advanced tip I’ll leave you with.
Use the module to create optimal internal linking. You already have the pages and the keywords, its a very easy to do and short revision. Pass the page text or the navigation to your module. Have it parse for all links. If it finds a link that matches the domain of the current page (useful variable) then have it grab the top keyword count for that other page and replace the anchor text. Boom! You just got perfectly optimized internal linking that will only get better over time. ![]()
There ya go naysayers. Now you can say you’ve learned a SEO technique that’s both pure white hat and no matter how simple you explain it very much advanced.